
原文链接:http://tecdat.cn/?p=23344
最近我们被客户要求撰写关于信用卡违约分析的研究报告,包括一些图形和统计输出。
本文中我们介绍了决策树和随机森林的概念,并在R语言中用逻辑回归、回归决策树、随机森林进行信用卡违约数据分析
决策树是由节点和分支组成的简单树状结构。根据每个节点的任何输入特征拆分数据,生成两个或多个分支作为输出。这个迭代过程增加了生成的分支的数量并对原始数据进行了分区。这种情况一直持续到生成一个节点,其中所有或几乎所有数据都属于同一类,并且不再可能进一步拆分或分支。
这整个过程生成了一个树状结构。第一个分裂节点称为根节点。末端节点称为叶子并与类标签相关联。从根到叶的路径产生分类规则。

假设你是一名员工,你想吃食物。
您的行动方案将取决于多种情况。
如果你不饿,你就不会花钱。但是如果你饿了,那么选择就会改变。你的下一步行动取决于你的下一个情况,即你有没有买午餐?
现在,如果你不吃午饭,你的行动将完全取决于你的下一个选择,即是不是月底?如果是月底最后几天,可以考虑不吃饭;否则,您不会将其视为偏好。
当涉及多个选择来做出任何决定时,决策树就会发挥作用。现在你必须做出相应的选择以获得有利的结果。

决策树如何工作?
决策树有两个组成部分:熵和信息增益
熵是一个用来衡量信息或无序的概念。我们可以用它来衡量数据集的纯度。
为了更好地理解熵,让我们研究两个不同的示例数据集,它们都有两个类,分别表示为蓝点和红叉。在左侧的示例数据集中,我们混合了蓝点和红叉。在右侧数据集的示例中,我们只有红十字。第二种情况——一个只有一个类样本的数据集——是我们的目标:一个“纯”数据子集。
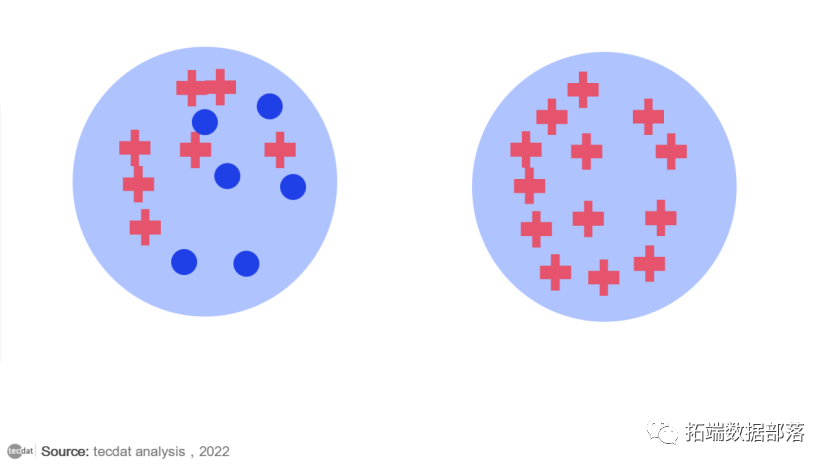
熵可以是纯度、无序或信息的量度。由于混合类,左边的数据集不那么纯净,更混乱(更无序,即更高的熵)。然而,更多的混乱也意味着更多的信息。实际上,如果数据集只有一类的点,那么无论您尝试多长时间,都无法从中提取太多信息。相比之下,如果数据集具有来自两个类的点,则它也具有更高的信息提取潜力。所以,左边数据集的熵值越高,也可以看作是潜在信息量越大。
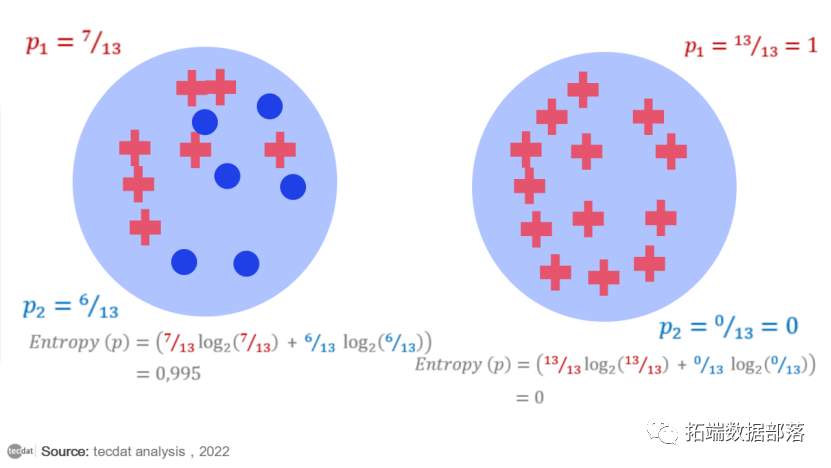
信息增益为了评估一个特征对分裂的好坏,计算分裂前后的熵差。
决策树中每个拆分的目标是从混淆的数据集移动到两个(或更多)更纯的子集。理想情况下,分裂应该导致熵为 0.0 的子集。然而,在实践中,如果拆分导致子集的总熵低于原始数据集就足够了。
也就是说,我们首先计算分割前数据集的熵,然后计算分割后每个子集的熵。最后,在拆分之前从数据集的熵中减去由子集大小加权的输出熵之和。这种差异衡量了信息的增益或熵的减少。如果信息增益是一个正数,这意味着我们从一个混乱的数据集转移到了一些更纯粹的子集。
然后,在每一步,我们将选择在信息增益值最高的特征上分割数据,因为这会产生最纯粹的子集。
我们将首先分割信息增益最高的特征。这是一个递归过程,直到所有子节点都是纯的或直到信息增益为零。

随机森林
随机森林是另一种强大且最常用的监督学习算法。
许多比一个好。简单来说,这就是随机森林算法背后的概念。也就是说,许多决策树可以产生比仅仅一棵决策树本身更准确的预测。事实上,随机森林算法是一种有监督的分类算法,它构建了 N 个经过稍微不同训练的决策树,并将它们合并在一起以获得更准确和稳定的预测.
让我们再次强调这个概念。整个想法依赖于多个决策树,这些决策树都经过略微不同的训练,并且所有这些决策树都被考虑到最终决策中。
在一个随机森林中,N 棵决策树在通过获得的原始训练集的一个子集上进行训练自举原始数据集,即通过带放回的随机抽样。
此外,输入特征也可能因树而异,作为原始特征集的随机子集。
N 个稍有不同训练的树将对相同的输入向量产生 N 个稍有不同的预测。通常,多数规则适用于做出最终决定。N棵树中的大多数提供的预测被用作最后一棵。
这种策略的优势是显而易见的。虽然来自单个树的预测对训练集中的噪声高度敏感,但来自大多数树的预测却不是——前提是这些树不相关。Bootstrap 采样是通过在不同的训练集上训练树来去相关树的方法。

接下来,我们在R语言中用逻辑回归、回归决策树、随机森林进行信用卡违约分析。
**
**
信贷数据集,其中包含了银行贷款申请人的信息。该文件包含1000名申请人的20条信息。
下面的代码可以用来确定申请人是否有信用,以及他(或她)是否对贷款人有良好的信用风险。有几种方法被应用到数据上,帮助做出这种判断。在这个案例中,我们将看一下这些方法。
相关视频Boosting原理与R语言提升回归树BRT预测短鳍鳗分布
**
拓端
,赞16
请注意,本例可能需要进行一些数据处理,以便为分析做准备。
我们首先将数据加载到R中。
credit 这段代码在数据上做了一个小的处理,为分析做准备。否则,就会出现错误,因为在某些文件的某一列中发现有四类因素。
基本上,任何4类因变量都被覆盖为3类。继续进行分析。
No.of.Credits[No.of.Credits == 4] 快速浏览一下数据,了解一下我们的工作内容。
str(credit)
你可能会立即注意到有几个变量很显眼。我们要排除它们。”信贷期限(月)”、”信贷金额 “和 “年龄”。
为什么?
我们在这个模型中试图把重点放在作为信用价值指标的数据分类或类别上。这些是分类变量,而不是数字变量。申请人有电话吗?申请人是否已婚?是否有共同签署人?申请人在同一地址住了多长时间?这类事情。
关于这些因素,重要的是我们知道它们与贷款决定的关系。良好的信用与某些因素的组合有关,从而使我们可以用概率将新的申请人按其特征进行分类。
在数据中,这些问题的答案不是 “是 “或 “不是 “或 “十年”。答案被分组为更广泛的分类。
我们需要做的是删除真正的数字数据(时间、金额和年龄),保留分类因素。我们排除选定列。
然后我们创建一个简短的函数,将整数转换成因子。
for(i in S) credit[, i] 现在我们有了有用的数据,我们可以开始应用不同的分析方法。
方法一:_逻辑回归_(Logistic Regression)
第一步是创建我们的训练数据集和测试数据集。训练集用于训练模型。测试集则用于评估模型的准确性。
我们把数据集分成任何我们喜欢的大小,在这里我们使用三分之一,三分之二的分割。
(1:nrow(credit))[-sample(1:nrow(credit), size = 333)]在这个阶段,我们将使用glm()函数进行Logistic回归。在这里,我们有选择地使用模型中的变量。但现在只是用五个变量来确定信用度的值。
LogisticModel完成后,我们继续将我们刚刚创建的模型拟合到测试集i_test1上,并准备进行第一次预测。
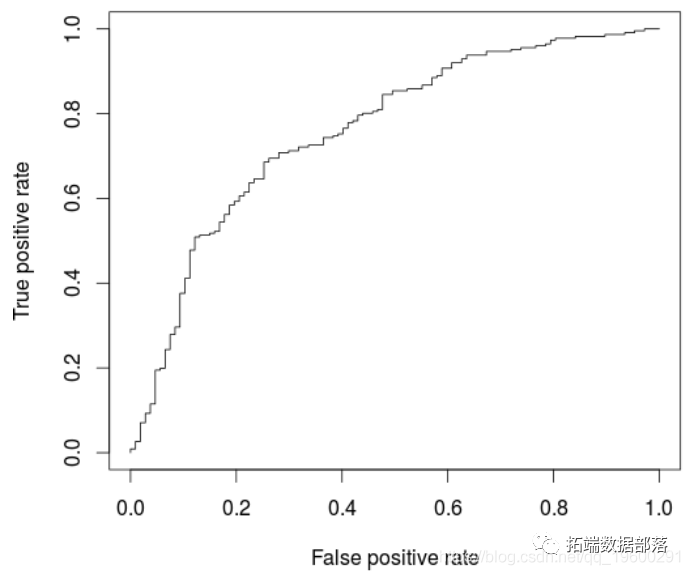
我们已经拟合了模型。现在我们将使用ROCR包来创建预测,并以曲线下面积(AUC)来衡量性能。AUC越大,说明我们的模型表现越好。
perf1 让我们描绘一下结果。

我们将通过寻找AUC来结束这一部分。
AUCLog1
这不是一个糟糕的结果,但让我们看看是否可以用不同的方法做得更好。
方法二:另一种Logistic模型
在这种方法中,我们将建立第二个Logistic逻辑模型来利用我们数据集中的所有变量。其步骤与上述第一个模型相同。
perf2 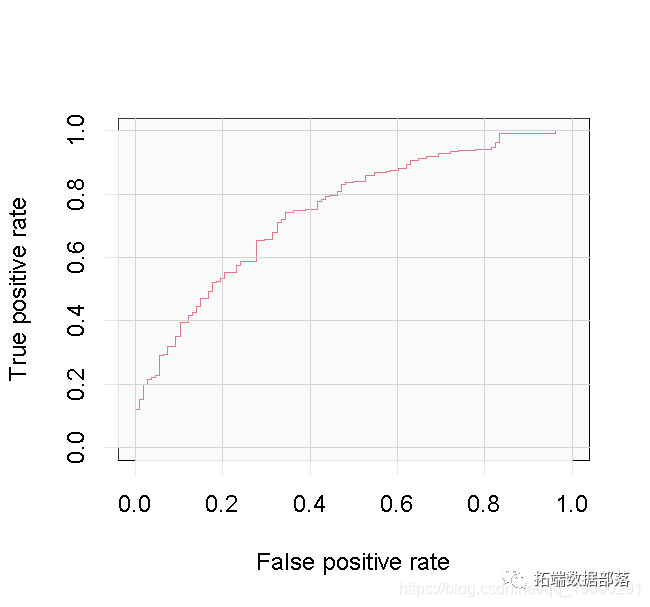
AUCLog2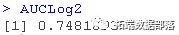
包括所有的变量,我们并没有得到多少改善。一个好的规则是尽可能保持模型的简单。增加更多的变量会带来很少的改善,所以坚持使用更简单的模型。
点击标题查阅往期内容

R语言用逻辑回归、决策树和随机森林对信贷数据集进行分类预测

左右滑动查看更多

01
02
03
04
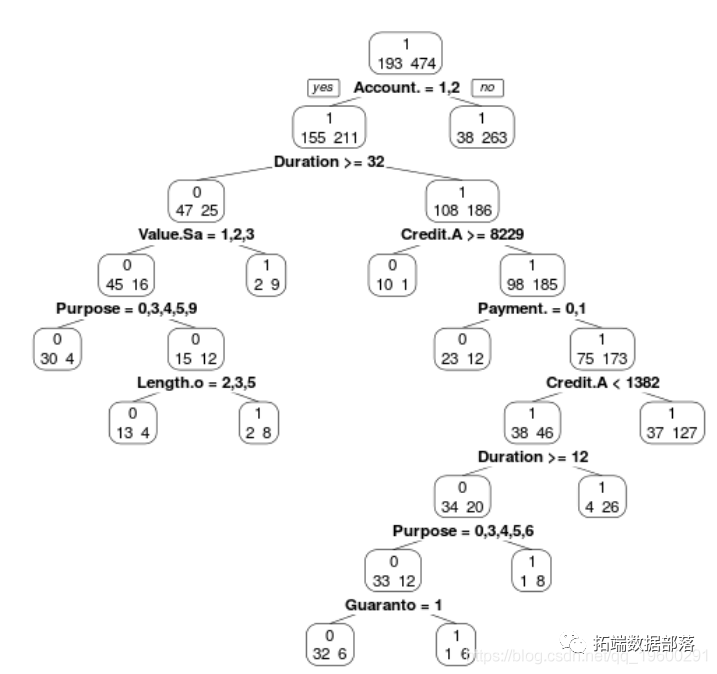
方法三:回归树
接下来,让我们试着用回归树的方法来分析数据。我们的大部分代码与上述逻辑模型中使用的代码相似,但我们需要做一些调整。
请再次注意,我们正在研究我们模型中的所有变量,找到它们对我们感兴趣的变量–信用度的影响。
TreeModel 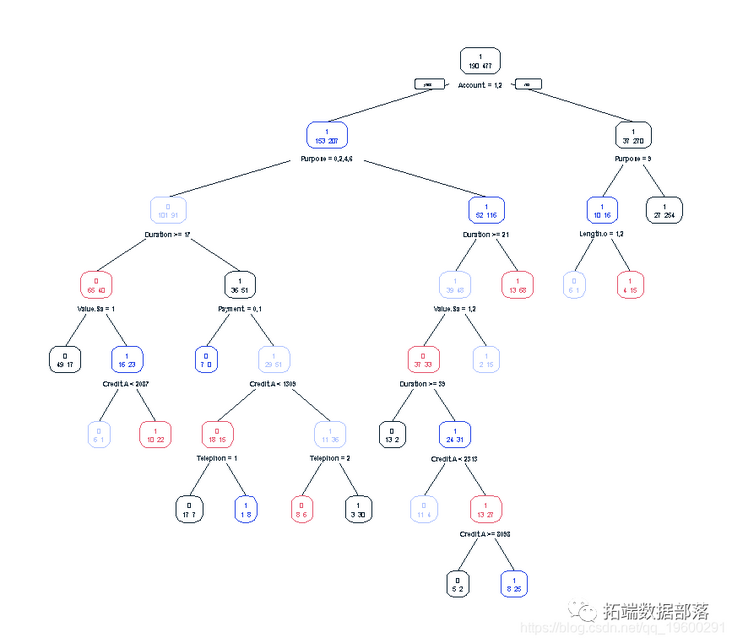
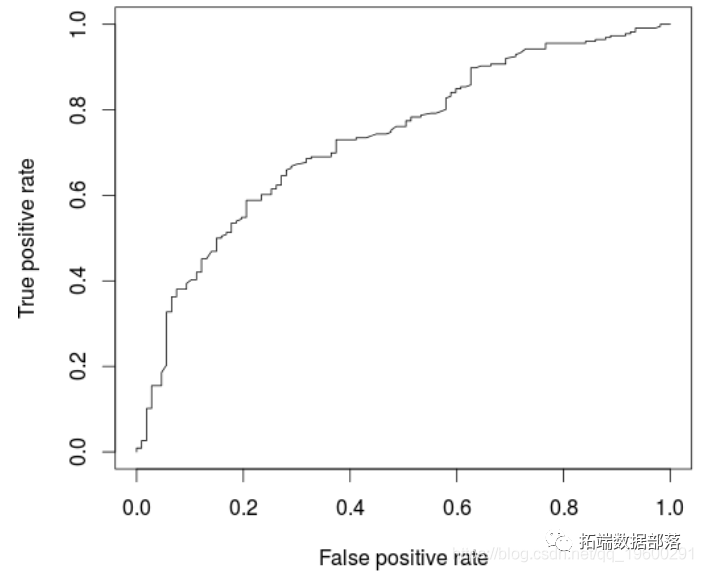
perf3 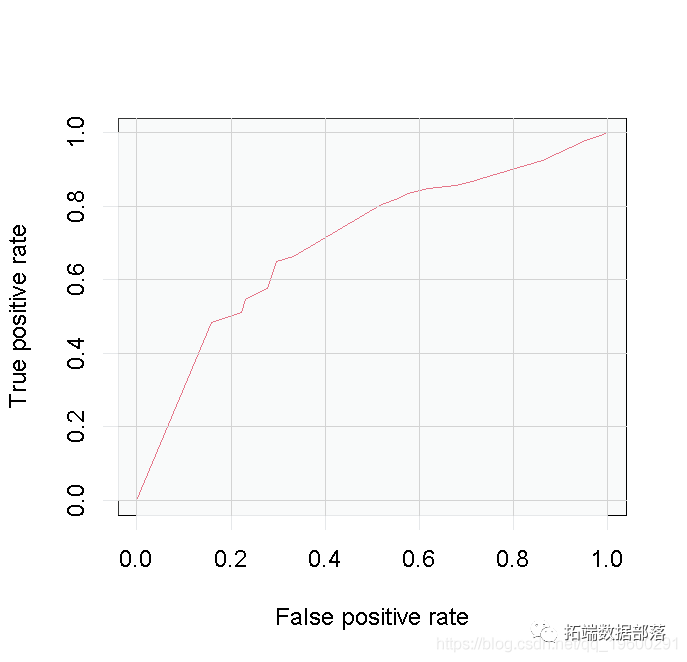

考虑到我们的树状模型的复杂性,这些结果并不令人满意,所以我们不得不再次怀疑第一个例子中更简单的Logistic Regression模型是否更好。
方法四:随机森林
与其建立一棵决策树,我们可以使用随机森林方法来创建一个决策树 “森林”。在这种方法中,最终结果是类的模式(如果我们正在研究分类模型)或预测的平均值(如果我们正在研究回归)。
随机森林背后的想法是,决策树很容易过度拟合,所以找到森林中的 “平均 “树可以帮助避免这个问题。
你可以想象,这比创建一棵决策树在计算上要求更高,但R可以很好地处理这一工作。
randomForest(Credit ~ )
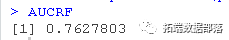
通过努力,我们得到了一个有点改进的结果。随机森林模型是我们所尝试的四个模型中表现最好的。但是,这需要判断结果是否值得付出额外的努力。
方法五:比较随机森林和Logistic模型
好了,我们已经看了使用两种基本分析方法的各种结果–逻辑回归和决策树。我们只看到了以AUC表示的单一结果。
随机森林方法要求我们创建一个决策树的森林,并取其模式或平均值。为什么不利用所有这些数据呢?它们会是什么样子呢?
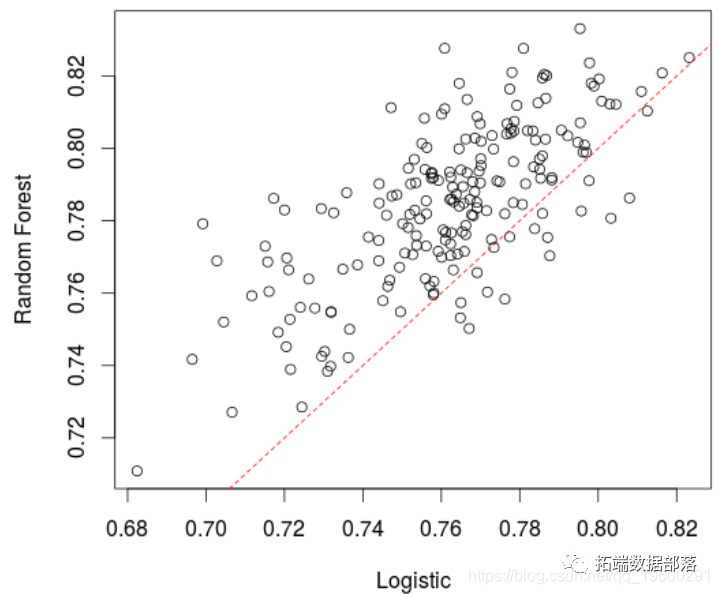
下面的代码创建了一个图表,描述了我们的随机森林中每棵树的AUC分数和逻辑模型的数百种组合。
首先我们需要一个函数来进行分析。
function(i){
i_test2 这部分代码的运行需要一段时间,因为我们要对数百个单独的结果进行列表和记录。你可以通过改变VAUC对象中的计数来调整模型中的结果数量。在这里,我们选择计算200个x-y对,或400个单独的结果。
plot(t(VC))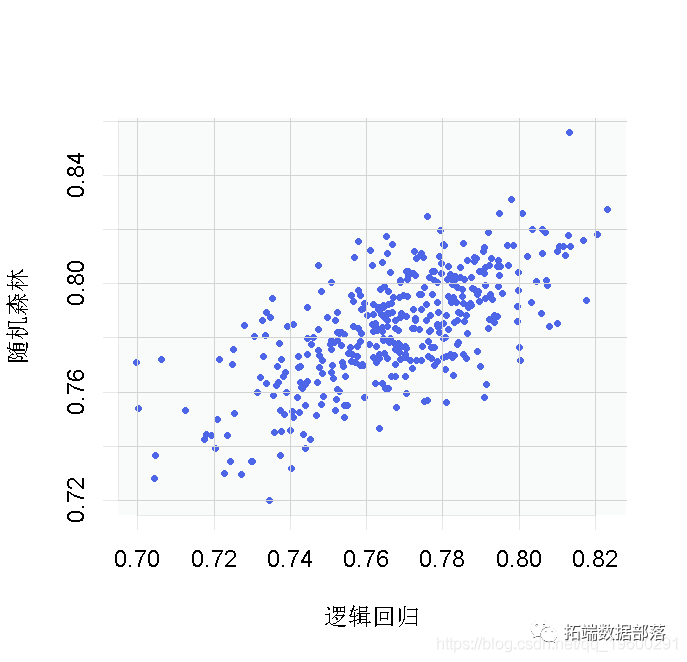
你可以看到,我们从前四个模型中得到的结果正好处于分布的中间。
这为我们证实了这些模型都是有可比性的。我们所希望的最好结果是AUC达到0.84,而且大多数人给我们的结果与我们已经计算的结果相似。
但是,让我们试着更好地可视化。
首先,我们将对象转换成一个数据框架。
我们创建几个新图。第一个是密度等高线图。
plot(AA, aes(x = V1, y = V2)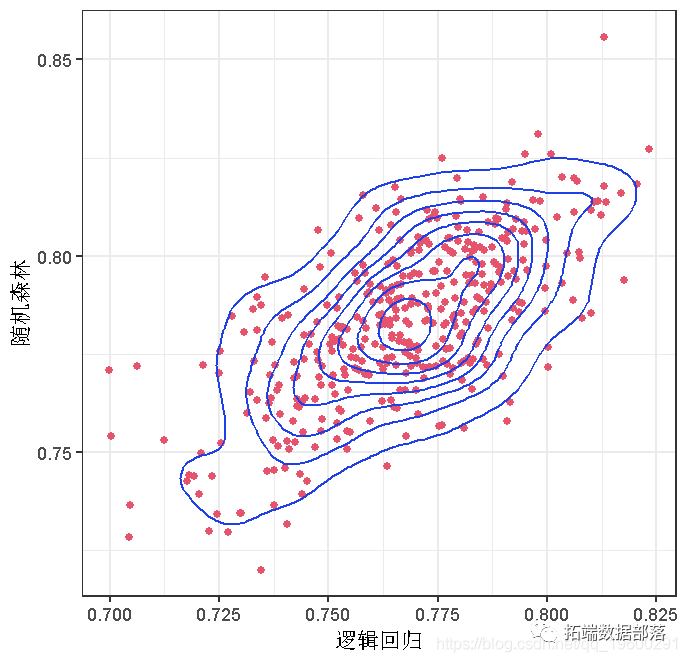
第二张是高密度等高线图,给我们提供了数据的概率区域。
with(AA, boxplot(V1, V2))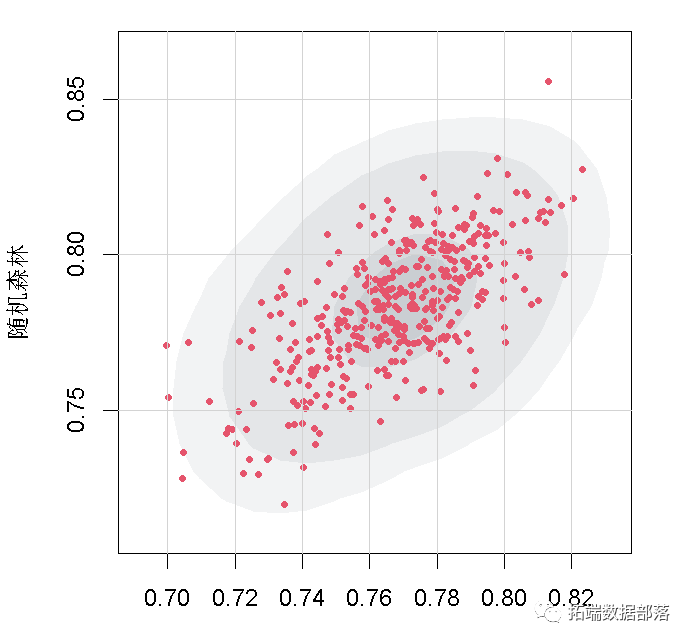
无论我们以何种方式描述我们的结果,都必须使用数据来做出合理的贷款决定。这里有一个问题?
这些可能是我们使用这些模型所能得出的最佳分数,但这些结果对于确定贷款申请人的信用价值是否可以接受?这取决于贷款机构所使用的信用标准。
在最好的情况下,看起来我们的模型给了82%的机会向良好的信用风险提供贷款。对于每100万元的贷款,我们最多可能期望得到82万元的偿还。平均而言,我们预计会收回大约78万元的本金。换句话说,根据我们的分析,有75%到80%的机会重新获得100万元的贷款,这取决于我们使用的建模方法。
当我们把贷款申请人加入我们的数据库时,如果我们要把他们视为良好的信贷风险,我们希望他们聚集在高密度图的最暗区域。
除非我们收取大量的利息来弥补我们的损失,否则我们可能需要更好的模型。

点击文末 “阅读原文”
获取全文完整资料。
本文选自《R语言逻辑回归(Logistic Regression)、回归决策树、随机森林信用卡违约分析信贷数据集》。
点击标题查阅往期内容
PYTHON用户流失数据挖掘:建立逻辑回归、XGBOOST、随机森林、决策树、支持向量机、朴素贝叶斯和KMEANS聚类用户画像
Python对商店数据进行lstm和xgboost销售量时间序列建模预测分析
PYTHON集成机器学习:用ADABOOST、决策树、逻辑回归集成模型分类和回归和网格搜索超参数优化
R语言集成模型:提升树boosting、随机森林、约束最小二乘法加权平均模型融合分析时间序列数据
Python对商店数据进行lstm和xgboost销售量时间序列建模预测分析
R语言用主成分PCA、 逻辑回归、决策树、随机森林分析心脏病数据并高维可视化
R语言基于树的方法:决策树,随机森林,Bagging,增强树
R语言用逻辑回归、决策树和随机森林对信贷数据集进行分类预测
spss modeler用决策树神经网络预测ST的股票
R语言中使用线性模型、回归决策树自动组合特征因子水平
R语言中自编基尼系数的CART回归决策树的实现
R语言用rle,svm和rpart决策树进行时间序列预测
python在Scikit-learn中用决策树和随机森林预测NBA获胜者
python中使用scikit-learn和pandas决策树进行iris鸢尾花数据分类建模和交叉验证
R语言里的非线性模型:多项式回归、局部样条、平滑样条、 广义相加模型GAM分析
R语言用标准最小二乘OLS,广义相加模型GAM ,样条函数进行逻辑回归LOGISTIC分类
R语言ISLR工资数据进行多项式回归和样条回归分析
R语言中的多项式回归、局部回归、核平滑和平滑样条回归模型
R语言用泊松Poisson回归、GAM样条曲线模型预测骑自行车者的数量
R语言分位数回归、GAM样条曲线、指数平滑和SARIMA对电力负荷时间序列预测R语言样条曲线、决策树、Adaboost、梯度提升(GBM)算法进行回归、分类和动态可视化
如何用R语言在机器学习中建立集成模型?
R语言ARMA-EGARCH模型、集成预测算法对SPX实际波动率进行预测在python 深度学习Keras中计算神经网络集成模型R语言ARIMA集成模型预测时间序列分析R语言基于Bagging分类的逻辑回归(Logistic Regression)、决策树、森林分析心脏病患者
R语言基于树的方法:决策树,随机森林,Bagging,增强树
R语言基于Bootstrap的线性回归预测置信区间估计方法
R语言使用bootstrap和增量法计算广义线性模型(GLM)预测置信区间
R语言样条曲线、决策树、Adaboost、梯度提升(GBM)算法进行回归、分类和动态可视化
Python对商店数据进行lstm和xgboost销售量时间序列建模预测分析
R语言随机森林RandomForest、逻辑回归Logisitc预测心脏病数据和可视化分析
R语言用主成分PCA、 逻辑回归、决策树、随机森林分析心脏病数据并高维可视化
Matlab建立SVM,KNN和朴素贝叶斯模型分类绘制ROC曲线
matlab使用分位数随机森林(QRF)回归树检测异常值
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
