
在使用redis缓存时,我们大概都听过缓存击穿、缓存雪崩之类的场景和方案,这也是一般常见面试题的内容。但在这些年的实际开发中,的确亲身经历了这类场景之后,对这类场景和解决方案就更加深刻,这类再统一总结一下。
当然方案不是唯一的,后续如果我用到更好的方案,依然会基于本文档补充。
1. 缓存击穿
1.1. 定义
缓存击穿,也就是说当redis缓存中有一个key是大量请求同时访问的热点数据,如果突然这个key时间到了,那么大量的请求在缓存中获取不到该key,穿过缓存直接来到数据库导致数据库崩溃,这样因为单个key失效而穿过缓存到数据库称为缓存击穿。
1.2. 方案
1.2.1. 方案一:主动更新key
这里问题在于key是被动刷新的,即key过期后自动删除,当流量请求进来了才去读db更新缓存。如果场景允许,我们可以主动控制性的刷新key。key依然可以设置过期时间,但我们可以通过后台job等方式,从db拿最新的值更新key对应的value,更新的同时自然对key进行续期。
这样以达到能定时更新redis值,又保证redis key永远不失效,突发大流量也走不到db。
1.2.2. 方案二:更新缓存加锁
缓存击穿的场景在压测中经常可见,当没有缓存预热时,redis 缓存key一开始不存在。假设jmeter 100个线程并发访问时,都发现缓存key不存在,100个请求都会去查询db,然后更新redis值。
其实我们在发现key不存在之后,可以对于“查db更新redis缓存”这个过程加上分布式锁,保证只要有一个请求去读db、更新缓存。其他的请求在等待锁释放后,再去查下redis缓存。此时缓存有值就直接访问缓存。
2. 缓存雪崩
2.1. 定义
当大量请求在访问都会先从缓存查询,如果此时大部分缓存同时过期失效,那么这些请求都查询不到缓存,此时他们会全部将请求到数据库,当请求数量足够大时此时将会把数据库压垮,这就是缓存雪崩。比如:在凌晨十二点搞促销,大约有10000个用户发起请求,此时缓存过期,则这10000个请求直接打到数据库上,把数据库压垮,即使重启数据库请求依然会打到数据库上。
这里和“缓存击穿”不同的地方在于:
- 缓存击穿:单个key过期,单个key的大量请求进来。
- 缓存雪崩:多个key同时过期,多个key的大量请求进来。
2.2. 方案
2.2.1. 方案一:过期时间分散
问题在于key同时过期。首先,如果业务上key的生成时间不是同时的,那么过期时间也就不是同时的,这类问题可以避免。
如果key的生成时间是同时的,例如:缓存是通过job或其他触发条件批量一起生成的,那么在定义每个key的过期时间时,可以基于原定的时间再加上一个随机时间段,以保障最终的过期时间不一致。
2.2.2. 方案二:集群架构
redis的集群架构中,可根据写入命令按照不同slot,分配在不同master上。因为这些key是不同的,针对缓存雪崩场景,写入的请求就可以分配在不同master节点上,能缓解一部分压力。
当然,效果有限,但至少比单体架构抗压强。
2.2.3. 方案三:降级限流
可评估数据库能接受的最大请求量,做限流。那么被限住的请求就要做服务降级,可在队列中等待异步更新redis值。
3. 缓存穿透
3.1. 定义
指当请求查询缓存和数据库都不存在的数据时,先查询缓存为空,再查询数据库依然为空,向请求返回空,如果大量请求同时访问这些不存在key那么这些请求依然会造成压垮数据库的现象,这种通常是恶意查询和被攻击几率较大。
缓存穿透 和 缓存击穿 名字听起来很像,但不是一回事。缓存穿透 是针对缓存中不存在的key。而 缓存击穿 是原本存在某个缓存key,等失效后突然大批量访问这个key。
3.2. 方案
3.2.1. 缓存null值
当访问一些不存在的key时,因为在db中查到的值为null,就不会缓存下来,所以下次访问依然会走db。
那么当在db中查到的值为null时,我们干脆就创建一个缓存key,存的值就为null等。当下次访问的时候,就会走缓存中取,而不用走db。
但是这个方案有局限性,得看具体场景。假设第一次访问的时候不存在,我们缓存了一个null的key,很快db中对应的key就有值了,可我们访问时依然是从缓存中获取了null。
有两种改进策略:
- 可以针对null的值,我们的过期时间可以设短一点。(下策)
- 当db中值新建、更新时,能够主动清除对应的缓存key。(上策)
3.2.2. 布隆过滤器
详见 《布隆过滤器 与 Redis BitMap》
4. 热点key(缓存击穿)
4.1. 定义
这里 (缓存击穿),是因为和缓存击穿场景有点像。前面说的缓存击穿,单指key过期,大流量击穿db。而这里不用等到key过期,直接更大的流量,击穿redis,再击穿db。
热点key,就是瞬间有大量的请求去访问redis上某个固定的key。例如一些热搜词条:IG夺冠、梅西夺冠,一瞬间会有大量的用户请求都访问固定的词条,如果这些词条内容存在redis中,那么访问的就是某个固定的key。
我们知道,就算是redis的集群机构,针对某个固定的key,也是被分配某个固定的哈希槽上,对应redis某单个节点。而redis单个节点的性能有限,此时就容易被击溃,带来的危害有:
1. 流量集中,达到物理网卡上限
当某一热点Key的请求在某一节点所在的主机上超过该主机网卡流量上限时,由于流量的过度集中,会导致该节点的服务器中其它服务无法进行
2. 请求过多,缓存分片服务被打垮
Redis单点查询性能是有限的,单节点QPS差不多也就几万,当热点key的查询超过Redis节点的性能阈值时,请求会占用大量的CPU资源,影响其他请求并导致整体性能降低;严重时会导致缓存分片服务被打垮,表现形式之一就是Redis节点自重启,此时该节点存储的所有key的查询都是不可用状态,会把影响辐射到其他业务上。
3. 集群架构下,产生访问倾斜
即某个数据分片被大量访问,而其他数据分片处于空闲状态,可能引起该数据分片的连接数被耗尽,新的连接建立请求被拒绝等问题。
4. DB 击穿,引起业务雪崩
热Key的请求压力数量超出Redis的承受能力易造成缓存击穿,当缓存挂掉时,此时再有请求产生,可能直接把大量请求直接打到DB层上,由于DB层相对缓存层查询性能更弱,在面临大请求时很容易发生DB雪崩现象,严重影响业务。
4.2. 识别热点key
4.2.1. 业务经验评估
比如热搜关键词、秒杀商品的词条等等,能够提前识别到可能是热点key的,就提前做准备。
4.2.2. 业务侧监控
在操作redis之前,加入一行代码进行数据统计,异步上报行为;如类似日志采集,将单次redis命令的操作/结果/耗时等统计,异步消息发送给采集消息队列,缺点就是对代码造成入侵,一般可以交给中间件加在自己包的redis二方包中;如果有做的好一点的Daas平台,可以在proxy层做监控,业务无需感知,统一在Daas平台查看redis监控。
4.2.3. redis服务器端监控
redis自带一些监控命令,可由运维侧基于redis的命令,提供一些监控平台。
1. monitor命令
该命令可以实时抓取出redis服务器接收到的命令,然后写代码统计出热key是啥;当然,也有现成的分析工具可以给你使用,比如redis-faina;但是该命令在高并发的条件下,有内存增暴增的隐患,还会降低redis的性能。
2. hotkeys参数
redis 4.0.3提供了redis-cli的热点key发现功能,执行redis-cli时加上–hotkeys选项即可;但是该参数在执行的时候,如果key比较多,执行起来比较慢。
4.3. 方案
4.3.1. 二级缓存
针对热点key做二级缓存,将流量分摊到java各个节点的内存中,也减少了网络带宽。
当然,二级缓存带来的缺点就是难维护缓存的一致性。不过这也算是针对热点key场景下的一种降级策略。
4.3.2. key副本拆分
可以将某个key的内容复制成多个key,如:xxkey_01、xxkey_02、xxkey_03…,这样这些key就会分散在不同的哈希槽中,不同的redis节点上。
在java代码每次请求redis key时,可以通过轮询等方式,访问不同key中的数据。就将流量平摊到不同的redis节点中。
前面是设置编号,访问时随机访问其中一个key。还可以考虑按照用户群体、访问场景等维度拆分,拆分生成不同的key,同样的思路,也是可以将流量拆分开。
4.3.3. 热点key redis集群隔离
如果财力允许,为了防止热点key引发问题时,核心业务不受影响,应当提前做好核心/非核心业务的Redis的隔离,至少热点key存在的redis集群应当与核心业务隔离开来。
4.4. 有赞TMC框架实行
有赞专门设计了一套框架解决热点key的问题,具体内容请看原文 《有赞透明多级缓存解决方案(TMC)设计思路》。下面做简单说明。
TMC 本地缓存整体结构分为如下模块:
- Jedis-Client:Java 应用与缓存服务端交互的直接入口,接口定义与原生 Jedis-Client 无异;
- Hermes-SDK:自研“热点发现+本地缓存”功能的 SDK 封装,Jedis-Client 通过与它交互来集成相应能力;
- Hermes 服务端集群:接收 Hermes-SDK 上报的缓存访问数据,进行热点探测,将热点 key 推送给 Hermes-SDK 做本地缓存;
- 缓存集群:由代理层和存储层组成,为应用客户端提供统一的分布式缓存服务入口;
- 基础组件:etcd 集群、Apollo 配置中心,为 TMC 提供“集群推送”和“统一配置”能力;
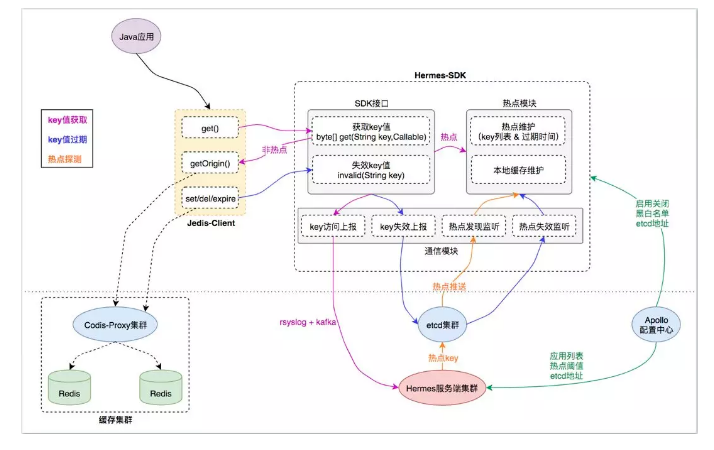
1. 监控
有赞改写了jedis原生的jar包,加入了Hermes-SDK包,目的就是做热点发现和本地缓存;
从监控的角度看,该包对于Jedis-Client的每次key值访问请求,Hermes-SDK 都会通过其通信模块将key访问事件异步上报给Hermes服务端集群,以便其根据上报数据进行“热点探测”。
2. 热key处理方案
在处理热key方案上,有赞用的是二级缓存。
有赞在监控到热key后,Hermes服务端集群会通过各种手段通知各业务系统里的Hermes-SDK,告诉他们这个key是热key,要做本地缓存。 于是Hermes-SDK就会将该key缓存在本地,对于后面的请求;Hermes-SDK发现这个是一个热key,直接从本地中拿,而不会去访问集群;
3. 二级缓存一致性方案
Hermes-SDK的热点模块仅缓存热点key数据,绝大多数非热点key数据由缓存集群存储;
热点key变更导致value失效时,Hermes-SDK 通过etcd集群广播事件,异步失效业务应用集群中其他节点的本地缓存,保证集群最终一致。
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
