
变量:是容器,值是可变的,变化的。作用就是增强脚本的灵活性。各种shell环境中都使用了“变量”的概念。shell变量用来存放系统和用户需要使用的特定参数(值),而且这些参数可以根据用户的设定或系统环境的变化而相应变化。通过使用变量,shell程序能够提供更加灵活的功能,适应性更强。
变量(数学名词)_百度百科 (baidu.com)
变量的类型:自定义变量、预定义变量,环境变量。
1、自定义变量
自定义变量是由用户自己定义的变量,只在用户自己的shell环境中有效,因此又称为本地变量。在编写shell脚本程序时,通常会设置一些特定的自定义变量,以适应程序执行过程中的各种变化,满足不同的需要。
变量名:以字母或下划线开始,区分大小写,建议全大写。
定义变量:变量名=变量值(赋值)
查看变量值:echo $变量名
定义变量的基本格式为”变量名=变量值”,等号俩边没有空格。变量名称需以字母或下滑线开始,名称中不要包含特殊字符(如+、-、/、、?、%、&、#等)。
例如:

使用echo命令可以查看变量(可以在一条echo命令中同时查看多个变量值)。
例如:

当变量名称容易和紧跟其后的其他字符相混淆,需要添加大括号”{}”将其括起来,否则无法确定正确的变量名称。对于未定义的变量名称,将显示为空值。

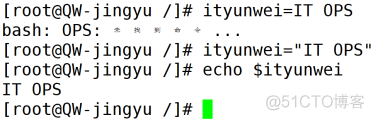
双引号(” “)
双引号主要起界定字符串的作用,允许通过$符号引用其他变量值特别是当要赋值的内容中包含空格时,必须以双引号括起来,
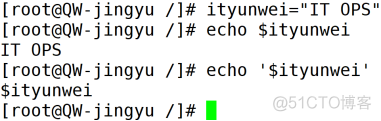
单引号(’ ‘)禁止引用其他变量值,赋值的内容中包含$、”、等具有特殊含义的字符时,应使用单引号括起来。任何字符均作为普通字符看待。
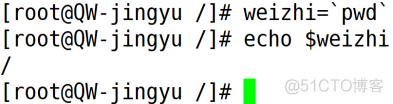
反撇号(`)
反撇号简单来说就是用于命令替换,允许将执行的某个命令的屏幕输出结果赋值给变量。反撇号括起来的范围内必须是能够执行的命令行,否则将会出错。
命令执行后的输出结果与$()效果一样的。
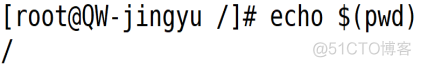
read命令
read 命令用来提示用 户输入信息,从而实现简单的交互过程。以空 格为分隔符。但一般为了提高易用性会结合”-p”选项来设置提示信 息,以便告知用户应该输入什么内容等相关事项。

数值变量的运算
在Bash Shell 环境中,只能进行简单的整数运算,不支持小数运算。整数值的运算主要通过内部命令expr进行,需要注意,运算符与变量之间必须有至少一个空格。
格式:expr 变量1 运算符 变量2 [运算符变量3]…
运算符:+:加法 -:减法 *:乘法 /:除法 %:取余(用来计算数值相除后的余数)
例如:
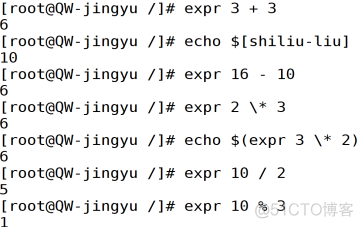
bc命令(计算更加精确的带有小数点的数字)了解就行。。。
但是要在前面加上scale选项,scale=*:表示精确到小数点后几位。(最多为六位数)。
例如:

若想将运算结果赋值给其他的变量,可以结合命令替换操作(使用反撇号)。
例如:

变量作用域(变量的有效范围,可使用的范围)
默认情况下,新定义的变量只在当前的shell环境中有效(默认情况下在shell脚本或shell函数中定义),称为局部变量。对其它的shell脚本和子进程都无效。
每个变量都有属于它的作用域,就是这些变量在什么范围内有效
默认情况下,新定义的变量只在当前的Shell环境中有效。进入子程序或新的子 Shell 环境时,将无法再使用。为了使用户定义的变量在所有的子 Shell环境中能够继续使用,可以通过内部命令 export 将指定的变量导出为全局变量。用户可以同时指定多个变量名称作为参数(无须使用“S”符号),变量名之间以空格分隔。
例如:
[root@localhost ~]# echo “$Product $Version” //查看当前定义的变量值
Python 2.7.13
[rootelocalhost ~]# export Product Version
[root@localhost ~]#bash
[root@localhost ~]#echo “$Product $Version”
Python 2.7.13
[root@localhost ~]# exit
//将 Product 、Version 设为全局变量
//进入子 She11 环境
//可以调用父 Shell 的全局变量
//返回原有的 Shell 环境
使用 e服务器托管网xport 导出全局变量的同时,也可以为变量进行赋值,这样在新定义全局变量时就不需要提前进行赋值了。
例如:
执行以下操作可以直接新建一个名为 FQDN 的全局变量。
[rootelocalhost ~]# export FQDN=”www.jb-aptech.com.cn”
[root@localhost ~]# echoSFQDN
www.jb-aptech.com.cn
环境变量:主要是在程序运行时需要提前设置的变量。只在当前shell中生效,当shell关闭时变量会丢失。
(使用env命令可以看到当前工作环境下的环境变量。)
PATH 命令所示路径,以冒号为分割
HOSTNAME 主机名
HOSTNAME 主机名
HOME 宿主目录
SHELL 显示当前Shell类型
USER 打印当前用户名
ID 打印当前用户id信息
PWD 显示当前所在路径
HISTSIZE 历史命令大小(默认为1000条)
HOSTNAME 显示当前主机名
PS1 定义主机命令提示符的
RANDOM 随机生成一个 0 至 32767 的整数
环境变量的全局配置文件为/etc/profile,在此文件中定义的变量作用于所有用 户。
除此之外,每个用户还有自己的独立配置文件~/.bash_profile。
PATH 变量用于设置可执行程序的默认搜索路径,当仅指定文件名称来执行命令程序时,Linux 系统将在 PATH 变量指定的目录范围查找对应的可执行文件,如果找不到则会提示“command not found”。
查看当前搜索路径

添加搜索路径
例如:将etc添加到搜索路径

预定义变量
预定义变量是由Bash程序预先定义好的一类特殊变量,用户只能使用预定义变量,而不能创建新的预定义变量,也不能直接为预定义变量赋值。预定义变量使用“$” 符号和另一个符号组合表示较常用的几个预定义变量的含义如下。
> S#: 表示命令行中位置参数的个数。
> S*: 表示所有位置参数的内容。
> S?: 表示前一条命令执行后的返回状态,返回值为0表示执行正确,返回任何非0值均表
示执行出现异常。
> s0: 表示当前执行的脚本或程序的名称。
条件测试操作
Shell中的test命令用于检查某个条件是否成立,可以进行数值、文件、字符三给方面的测试。
整数值比较
整数值比较指的是根据给定的两个整数值,判断第一个数与第二个数的关系,如是否大于、等于、小于第二个数。整数值比较的常用操作选项如下,使用时将操作选项放在要比较的两个整数之间。
> -eq: 第一个数等于 第二个数
> -ne: 第一个数不等于第二个数
> -gt: 第一个数大于第二个数
> -lt: 第一个数小于第二个数
> -le: 第一个数小于或等于第二个数
> -ge: 第一个数大于或等于第二个数
整数值比较在 Shell 脚本编服务器托管网写中的应用较多。
文件测试
文件测试指的是根据给定的路径名称,判断对应的是文件还是目录,或者判断文件是否可读可写、可执行等。
> -d: 测试是否为目录 (Directory)
> -e: 测试目录或文件是否存在 (Exist)
> -f: 测试是否为文件 (File)
> -r: 测试当前用户是否有权限读取 (Read)
> -w: 测试当前用户是否有权限写入 (Write)
> -x: 测试是否设置有可执行 (Excute) 权限
字符串比较
字符串比较通常用来检查用户输入、系统环境等是否满足条件,在提供交互式操作的 Shell 脚本 中,也可用来判断用户输入的位置参数是否符合要求。
> =:第一个字符串与第二个字符串相同
> !=:第一个字符串与第二个字符串不相同,其中“!”符号表示取反
> -z: 检查字符串是否为空(Zero), 对于未定义或赋予空值的变量将视为空串
逻辑测试
逻辑测试指的是判断两个或多个条件之间的依赖关系。当系统任务取决于多个不同的条件时,
根据这些条件是否同时成立或者只要有其中一个成立等情况,需要有一个测试的过程。
> &&:逻辑与,表示“而且”,只有当前后两个条件都成立时,整个测试命令的返回值才为0
(结果成立)。使用test命令测试时,“&&”可改为“-a”,
> ||:逻辑或,表示“或者”,只要前后两个条件中有一个成立,整个测试命令的返回值即为0
(结果成立)。使用test命令测试时,“|l”可改为“ -o”。
> !:逻辑否,表示“不”,只有当指定的条件不成立时,整个测试命令的返回值才为0(结
果成立)。
if 语句的结构
在 Shell 脚本应用中,if 语句是最为常用的一种流程控制方式,用来根据特定的条件测试结果, 分别执行不同的操作(如果……那么……)。
单分支if语句的基本类型分为三种:
1. 单分支 if 语句
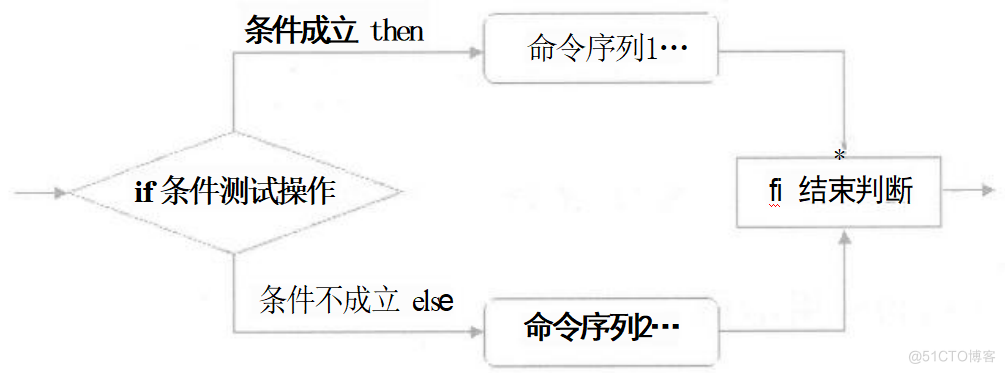
if 语句的“分支”指的是不同测试结果所对应的执行语句(一条或多条)。对于单分支的选择结 构,只有在“条件成立”时才会执行相应的代码,否则不执行任何操作。
单分支语法结构:
If 条件测试操作
then
符合条件的命令序列
fi
单分支 if 语句的执行流程:首先判断条件测试操作的结果,如果返回值为0,表示条件成立, 执行 then 后面的命令序列, 一直到遇见fi 结束判断为止,继续执行其他脚本代码;如果返回值不为 0,则忽略 then 后面的命令序列,直接跳至fi 行以后执行其他脚本代码。如下图:

2. 双分支 if 语句
对于双分支的选择结构,要求针对“条件成立”“条件不成立”两种情况分别执行不同的操作。
双分支if语法结构:
if 条件测试操作
then
符合条件的命令序列
Else
符合条件的命令序列
fi
双分支if 语句的执行流程:首先判断条件测试操作的结果,如果条件成立,则执行 then 后面的 命令序列1,忽略else及后面的命令序列2,直到遇见fi结束判断;如果条件不成立,则忽略then及后面的命令序列1,直接跳至else 后面的命令序列2并执行,直到遇见fi 结束判断,如图7.2所示.
多分支if语句
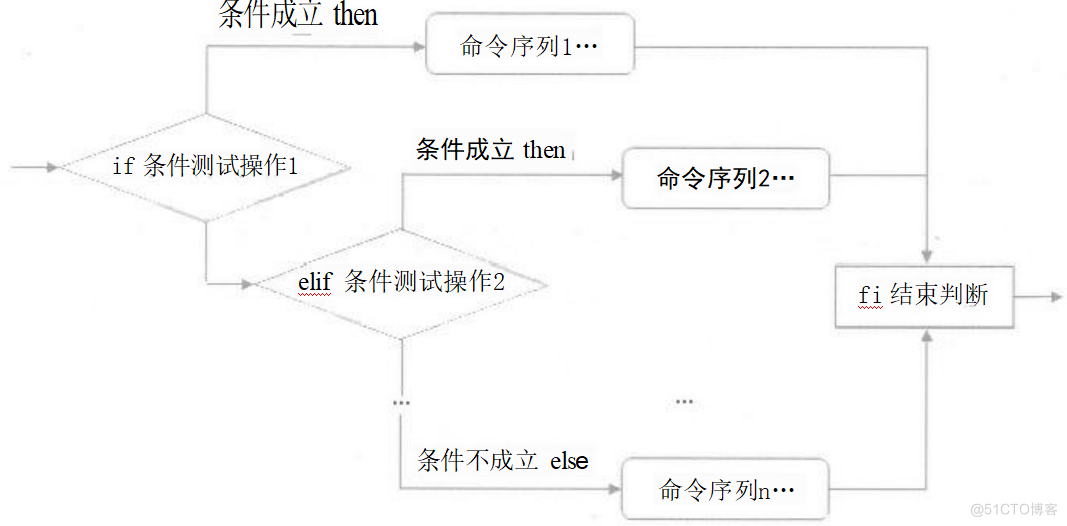
由于if语句可以根据测试结果的成立、不成立分别执行操作,所以能够嵌套使用,进行多次判断。
多分支if语句语法格式:
if条件测试操作1
then
命令序列1
elif条件测试操作2
then
命令序列2
else
命令序列3
fi
多分支if语句的执行流程:首先判断条件测试操作1的结果,如果条件1成立,则执行命令序列1,然后跳至fi结束判断;如果条件1不成立,则继续判断条件测试操作2的结果,如果条件2成立,则执行命令序列2,然后跳至fi结束判断……如果所有的条件都不满足,则执行else后面的命令序列n,直到遇见fi结束判断。
多分支的if 语句结构:
正则表达式
定义:正则表达式在代码中常简写为regex、regexp或RE。正则表达式是使用单个字符串来描述、匹配一系列符合某个句法规则的字符串,简单来说,是一种匹配字符串的方法,通过一些特殊符号,实现快速查找、删除、替换某个特定字符串。
正则表达式是由普通字符与元字符组成的文字模式。模式用于描述在搜索文本时要匹配的一个或多个字符串。正则表达式作为一个模板,将某个字符模式与所搜索的字符串进行匹配。其中普通字符包括大小写字母、数字、标点符号及一些其他符号,元字符则是指那些在正则表达式中具有特殊意义的专用字符,可以用来规定其前导字符(即位于元字符前面的字符)在目标对象中的出现模式。
基础正则表达式常见元字符:
|
元字符 |
作用 |
|
^ |
匹配输入字符串的开始位置。除非在方括号表达式中使用,表示不包含该字符集合。要匹配“^”字符本身,请使用“^” |
|
$ |
匹配输入字符串的结尾位置。如果设置了RegExp对象的Multiline属性,则“$”也匹配‘n’ 或‘r’。要匹配“$”字符本身,请使用“$” |
|
. |
匹配除“rn”之外的任何单个字符 |
|
将下一个字符标记为特殊字符、原义字符、向后引用、八进制转义符。例如,‘n’匹配字符“n”。‘n’匹配换行符。序列‘V’匹配“”,而‘(’则匹配“(” |
|
|
* |
匹配前面的子表达式零次或多次。要匹配“*”字符,请使用“*” |
|
[] |
字符集合。匹配所包含的任意一个字符。例如,“[abc]”可以匹配“plain”中的“a” |
|
[^] |
赋值字符集合。匹配未包含的一个任意字符。例如,“[^abc]”可以匹配“plain”中“plin”中的任何一个字母 |
|
[n1-n2] |
字符范围。匹配指定范围内的任意一个字符。例如,“[a-z]”可以匹配“a”到“z”范围内的任意一个小写字母字符。 |
|
{n} |
n是一个非负整数,匹配确定的n次。例如,“o{2}”不能匹配“Bob”中的“o”,但是能匹配“food”中的两个oo |
|
{n,} |
n是一个非负整数(正整数),至少匹配n次。例如,“o{2,}”不能匹配“Bob”中的“o”,但能匹配“foooood”中的所有o。“o{1,}”等价于“o+”。“o{0,}”则等价于“o*” |
|
{n,m} |
m和n均为非负整数,其中n |
扩展正则表达式
为了简化整改指令。需要使用范围更广的扩展正则表达式。
扩展正则表达式常见元字符:
|
元字符 |
作用 |
|
+ |
作用:重复一个或者一个以上的前一个字符 |
|
? |
作用:零个或者一个的前一个字符 |
|
| |
作用:使用或者(or)的方式找出多个字符 |
|
() |
作用:查找“组”字符串 |
|
()+ |
作用:辨别多个重复的组 |
文本处理器
grep,sed,awk 是shell编程中经常用到的文本处理工具,被称之为Shell 编程三剑客。
sed(Stream EDitor)是一个强大而简单的文本解析转换工具,可以读取文本,并根据指定的条件对文本内容进行编辑(删除、替换、添加、移动等),最后输出所有行或者仅输出处理的某些行。sed也可以在无交互的情况下实现相当复杂的文本处理操作,被广泛应用于Shell脚本中,用以完成
各种自动化处理任务。
sed的工作流程主要包括读取、执行和显示三个过程。
→ 读取:sed从输入流(文件、管道、标准输入)中读取一行内容并存储到临时的缓冲区中(又称模式空间,pattern space)。
> 执行:默认情况下,所有的sed命令都在模式空间中顺序地执行,除非指定了行的地址,
否则sed命令将会在所有的行上依次执行。
→ 显示:发送修改后的内容到输出流。再发送数据后,模式空间将会被清空。
1.sed命令常见用法
通常情况下调用sed命令有两种格式,如下所示。其中,“参数”是指操作的目标文件,当存在多个操作对象时用,文件之间用逗号“,”分隔;而scriptfile表示脚本文件,需要用“-f”选项指定,
当脚本文件出现在目标文件之前时,表示通过指定的脚本文件来处理输入的目标文件。
sed [选项 ] ‘操作’ 参数
sed [选项] -f scriptfile 参数
常见的sed命令选项:
> -e 或–expression=: 表示用指定命令或者脚本来处理输入的文本文件。
> -f 或–file=:表示用指定的脚本文件来处理输入的文本文件。
> -h 或–help:显示帮助。
> -n、–quiet或silent: 表示仅显示处理后的结果。
> -i:直接编辑文本文件。
“操作”用于指定对文件操作的动作行为,也就是sed的命令。通常情况下是采用的“[n1[,n2]]”操作参数的格式。n1、n2 是可选的,不一定会存在,代表选择进行操作的行数,如操作需要在5~20行之间进行,则表示为“5,20动作行为“。常见的操作包括以下几种。
>a: 增加,在当前行下面增加一行指定内容。
> c:替换,将选定行替换为指定内容。
> d:删除,删除选定的行。
> i: 插入,在选定行上面插入一行指定内容。
> p:打印,如果同时指定行,表示打印指定行;如果不指定行,则表示打印所有内容;如果有非打印字符,则以ASCll码输出。其通常与“-n”选项一起使用。
>s:替换,替换指定字符。
>y: 字符转换。
awk工具
通常情况下awk 所使用的命令格式如下所示,其中,单引号加上大括号“{}”用于设置对数据 进行的处理动作。awk 可以直接处理目标文件,也可以通过“-f”读取脚本对目标文件进行处理。简单来说。就是截取一行中的特定字段
awk选项‘ 模式或条件(编辑指令}’文件1文件2… //过滤并输出文件符条件的内容
awk-f脚本文件文件1文件2… //从脚本中调用编辑指令,过滤并输出内容
awk包含几个特殊的内建变量(可直接用)如下所示:
>FS:指定每行文本的字段分隔符,默认为空格或制表位。
>NF:当前处理的行的字段个数。
>NR:当前处理的行的行号(序数)。
>S0:当前处理的行的整行内容。
>Sn:当前处理行的第n个字段(第n列)。
>FILENAME:被处理的文件名。
>RS: 数据记录分隔,默认为n, 即每行为一条记录。
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
相关推荐: #yyds干货盘点# LeetCode程序员面试金典:单词规律
题目 给定一种规律 pattern 和一个字符串 s ,判断 s 是否遵循相同的规律。 这里的 遵循 指完全匹配,例如, pattern 里的每个字母和字符串 s 中的每个非空单词之间存在着双向连接的对应规律。 示例1: 输入: pattern = “abba…
