
引言
随着数字化浪潮下企业数字化转型进程的不断加速,以及云原生趋势下可观测性理念的逐渐普及,企业的日志数据来源越来越丰富, 数据规模也正在快速增长,为了高效处理分析这些数据, 日志的集中管理越来越有必要, 数据集中收集之后, 在需要的时候再查询和分析以充分挖掘这些数据的价值。
现在许多业务场景,对于高精度时服务器托管网间戳的需求越来越强烈,很多已经从秒、毫秒,变成了微秒和纳秒。 因为除了日志内容本身是一种重要信息之外,日志之间的相对顺序也是因果关系的一种反映,某些场景下如果日志内容完全相同,但是日志间的顺序错乱了反映出来的结果可能和真实世界里面的事件完全相反。接下来我们简要介绍下对日志顺序一致性有强烈需求的业务场景。
有序业务场景
随着云原生时代的到来,越来越多的业务对全局有序有强烈依赖,下面是几种常见的业务场景。
Trace
在现代IT系统中,尤其是云原生、微服务系统,一次外部请求往往需要多个内部服务、多个中间件和多台机器的相互调用才能完成。在这一系列的调用中,任何阶段出现的问题都可能导致外部服务失败或延迟升高,影响用户体验。如果您想要精确定位及分析问题,需要使用分布式链路追踪技术。
分布式链路追踪(Distributed Tracing,简称Trace)可提供整个服务调用链路的调用关系、延迟、结果等信息,非常适用于云原生、分布式、微服务等涉及多个服务交互的系统。
在跟踪(Trace)场景中,日志的纳秒级别排序对于后端日志处理系统具有重要意义。以下是日志纳秒级别排序对该场景的意义:
- 精确的时间戳关联
- 时序追溯
- 故障排查和性能优化
- 链路追踪
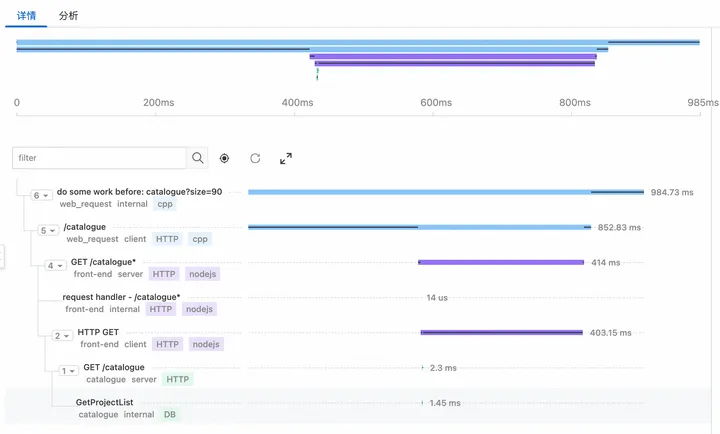
下图是某个trace调用下span的时间毫秒级别精度展示
高并发场景
在高并发场景下,全局排序好日志对于问题定位、时间线理清等方面具有重要性和意义。通过对日志进行排序,可以更好地理解系统行为,提高系统的可靠性、性能和可维护性。主要体现在下面几个方面:
- 跟踪和分析问题
- 理清时间线
- 监控和性能分析
强一致业务时序
在业务时序强一致的场景中,确保事件的顺序和时间的准确性非常重要。比如下面两个场景:
- 金融交易:在金融交易中,确保交易的顺序和时间的准确性非常关键。任何交易顺序的混乱或时间戳的错误都可能导致严重的后果,如资金损失或交易失败。因此,对于金融交易日志,确保按照nano级别进行排序和处理可以提供更高的时序一致性和准确性。
- 游戏竞技:在多人在线游戏或竞技平台中,确保事件的顺序和时间的准确性对于游戏结果和公平性非常重要。如果游戏事件的顺序混乱或时间戳错误,可能导致游戏结果的不准确或不公平。在处理游戏日志时,nano级别的排序和处理可以提供更精确的时序保证。
SLS支持全局有序和高精度时间戳
当前SLS已经支持高精度时间戳功能,并且直接按照纳秒级别进行全局排序。完美地满足了上述常见业务的全局排序需求。
相比老的非高精度时间戳的版本,会在以下PB结构新增了一个可选的Time_ns字段, 在开启高精度时间戳功能的时候,用来存放日志时间里面的纳秒部分。之所以新增这么一个字段, 而没有修改Time字段的类型主要是为了兼容历史数据。

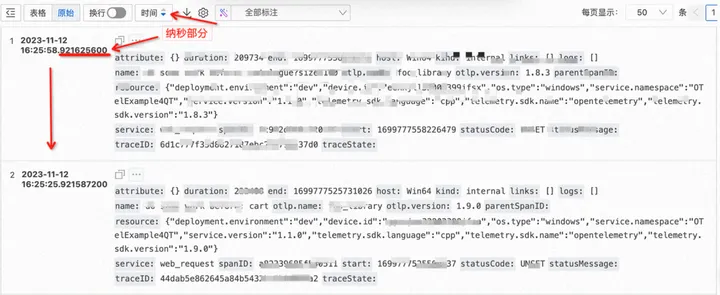
SLS会基于Time和Time_ns组合出来的nano时间全局排序, 控制台序查询结果如下服务器托管网图所示:
如何开启全局有序和nano高精度时间戳
从有序业务场景章节我们了解了全局有序对业务的重要性, 用户使用该功能, 需要从数据写入和查询两方面入手, 其中数据写入主要有两类途径,分别是logtail和sdk。
数据写入
- logtail
logtail可以帮助您无侵入式从服务器或容器中采集文件和标准输出日志,自1.8.2版本起支持nano高精度时间戳,安装和升级请参考帮助文档:https://help.aliyun.com/zh/sls/user-guide/install-logtail-on-a-linux-server
- 安装命令
./logtail.sh install {region}
- 升级命令
./logtail.sh upgrade
- 以上命令都可以使用-v参数指定版本,如
./logtail.sh upgrade -v 1.8.2
- logtail 开启nano采集配置
详情参考https://sls.aliyun.com/doc/dataaccess/enableTimeNano.html
- sdk
当前支持了go、c++、java、python, 如其他版本sdk有需要支持,可以通过工单提需求。
下面是python sdk写入带有nano时间部分的日志样例,用户可以根据具体业务需要,解析日志中正确的nano时间部分传入。后面查询的时候使用的是秒和纳秒部分两者拼接出来作为一个整体进行全局排序的。
def put_log_with_nano():
logitemList = []
for i in range(30):
contents = [
('DeviceIP', 11.22.33.55)
]
logItem = LogItem()
nano_time = time.time_ns()
sec_time = int(nano_time / 1000000000);
nano_time_part = nano_time % 1000000000;
logItem.set_time(sec_time)
logItem.set_time_nano_part(nano_time_part)
logItem.set_contents(contents)
logitemList.append(logItem)
request = PutLogsRequest(_project, _logstore, logitems=logitemList)
res = client.put_logs(request)
res.log_print()
数据查询
数据查询可以通过控制台或者sdk的方式。 控制台当前默认是nano级别排序,但是当前暴露的最小查询时间范围是1s, 如果要查询比秒级更小范围的查询,需要使用sdk, sdk语言版本支持情况同数据写入部分。
- 控制台
SLS控制台,会根据高精度的时间信息,自动进行显示优化,显示成毫秒、微秒、纳秒的形式.
- 微秒形式
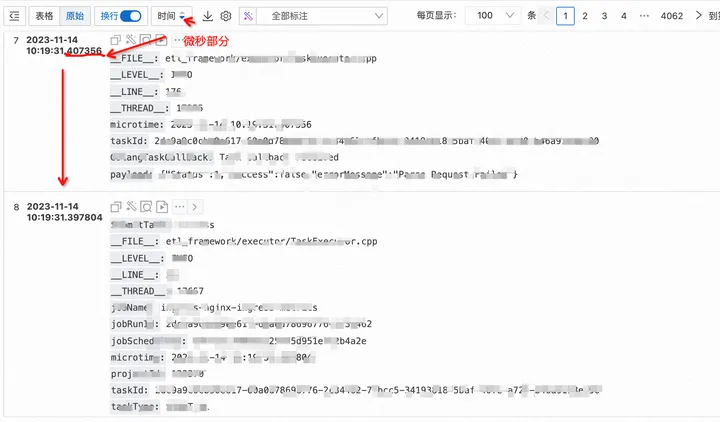
- 纳秒形式
- sdk
以python 为例, 捞取[1696743635 s, 1696743635 s +10 ns)区间内满足myQuery查询条件的最多100行log, 并以逆序输出返回结果。
新增参数说明:
- accurate_query设置为true默认走精确查询, 在设置为False情况下,只能保证分钟级别有序
- from_time_nano_part和to_time_nano_part 会分别和fromTime、toTime组合成nano时间范围去SLS查询,SLS会过滤出在这段纳秒时间范围内的满足查询条件的log,并以纳秒时间戳粒度有序输出
def query_log_with_nano():
query = "LEVEL:ERROR"
req = GetLogsRequest(_project, _logstore, fromTime=1696743635, toTime=1696743635, query=query, line=100, reverse=True, accurate_query=True, from_time_nano_part=0, to_time_nano_part = 10)
res = client.get_logs(req)
res.log_print()
基本原理简要介绍
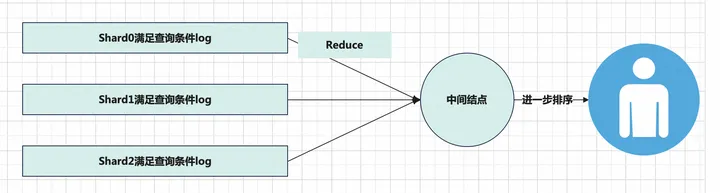
日志写入SLS的时候可能会落在不同的shard里面, 在查询的时候根据查询条件和查询时间范围,通过倒排索引和写入过程中存放的高精度时间信息来将各个shard内部满足条件的log过滤出来并返回给中间节点做进一步的全局排序处理,中间节点处理后再返回给用户。.
- 写入

- 查询
总结
SLS全局有序和高精度时间戳功能的支持解决了特定业务对日志顺序有严格要求的痛点, 通过该功能的升级,SLS能够更准确地对日志进行排序,为用户提供更加精准、可靠的时间顺序视图。
注意事项
nano python sdk目前发布在pypi官方源,国内某些镜像源可能还拉取不到,如果pip install -U aliyun-log-python-sdk 没有拉取到nano版本,可以用pip install -U aliyun-log-python-sdk==0.8.11获取到SLS支持。
SLS案例中心:https://sls.aliyun.com/doc/
原文链接
本文为阿里云原创内容,未经允许不得转载。
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
