
1-8main
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setAppName(s"${Transformation.getClass.getSimpleName}")
.setMaster("local[*]")
val sc = new SparkContext(conf)
// map(sc)
// flatMap(sc)
// filter(sc)
// sample(sc)
// union(sc)
// join(sc)
// gbk(sc)
// rbk(sc)
sc.stop()
}1.map
rdd.map(func):RDD,对rdd集合中的每一个元素,都作用一次该func函数,之后返回值为生成元素构成的一个新的RDD。
def map(sc: SparkContext): Unit = {
//设定范围,设置分区数量,一般这个分区数Spark会自动设置
val listRDD: RDD[Int] = sc.parallelize(1 to 7)
println("################listRDD的分区数:" + listRDD.getNumPartitions)
val ret = listRDD.map(num => num * 7)
ret.foreach(println)
}2.flatMap
rdd.flatMap(func):RDD ==>rdd集合中的每一个元素,都要作用func函数,返回0到多个新的元素,这些新的元素共同构成一个新的RDD。所以和上述map算子进行总结:
- map操作是一个one-2-one的操作
- flatMap操作是一个one-2-many的操作
//对集合中的字符串进行拆分
def flatMap(sc: SparkContext): Unit = {
val listRDD: RDD[String] = sc.parallelize(List(
"Hello World",
"nihao Spark",
"Good Bye hadoop"
))
//正则匹配
val wordsRDD: RDD[String] = listRDD.flatMap(line => line.split("\s+"))
wordsRDD.foreach(println)
}3.filter
rdd.filter(func):RDD ==> 对rdd中的每一个元素操作func函数,该函数的返回值为Boolean类型,保留返回值为true的元素,共同构成一个新的RDD,过滤掉哪些返回值为false的元素。
//保留3的倍数
def filter(sc: SparkContext): Unit = {
val listRDD = sc.parallelize(1 to 服务器托管网10)
val filteredRDD = listRDD.filter(num => num % 3 == 0)
filteredRDD.foreach(println)
}4.sample
rdd.sample(withReplacement:Boolean, fraction:Double [, seed:Long]):RDD ===> 抽样,需要注意的是spark的sample抽样不是一个精确的抽样。一个非常重要的作用,就是来看rdd中数据的分布情况,根据数据分布的情况,进行各种调优与优化。—>数据倾斜。
- withReplacement:抽样的方式,true有放回抽样, false为无返回抽样
- fraction: 抽样比例,取值范围就是0~1
- seed: 抽样的随机数种子,有默认值,通常也不需要传值
//抽样,true表示放回,false表示不放回
def sample(sc: SparkContext): Unit = {
val listRDD = sc.parallelize(1 to 1000000)
var sampledRDD = listRDD.sample(true, 0.1)
println("###########又放回的抽样结果:" + sampledRDD.count())
sampledRDD = listRDD.sample(false, 0.1)
println("###########无放回的抽样结果:" + sampledRDD.count())
}5.union
rdd1.union(rdd2),联合rdd1和rdd2中的数据,形成一个新的rdd,其作用相当于sql中的union all。
//将两个集合组合,不去重
def union(sc: SparkContext): Unit = {
val listRDD1 = sc.parallelize(List(1, 2, 4, 6, 7))
val listRDD2 = sc.parallelize(List(1, 5, 3, 6))
val unionRDD = listRDD1.union(listRDD2)
unionRDD.foreach(println)
}6.join
join就是sql中的inner join,join的效果工作7种。
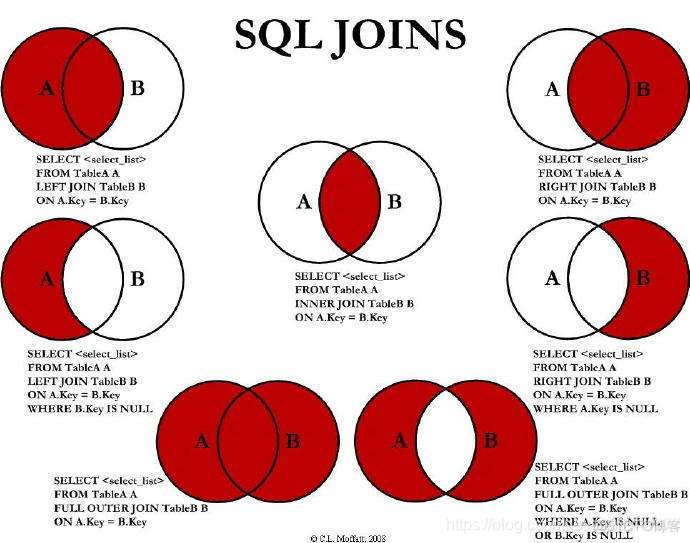
从具体的写法上面有如下几种
- 交叉连接
A a accross join B b;这种操作方式会产生笛卡尔积,在工作中一定要避免。 - 内连接
A a [inner] join B b [where|on a.id = b.id]; 有时候也写成:A a, B b(自连接) 是一种等值连接。所谓等值连接,就是获取A和B的交集。 - 外连接
- 左外连接
以左表为主体,查找右表中能够关联上的数据,如果管理不上,显示null。
A a left outer join B b on a.id = b.id。 - 右外连接
是以右表为主体,查找左表中能够关联上的数据,如果关联不上,显示null。
A a right outer join B b on a.id = b.id。 - 全连接
就是左外连接+右外连接
A a full outer join B b on a.id = b.id。 - 半连接
一般在工作很少用
sparkcore中支持的连接有:笛卡尔积、内连接join,外连接(左、右、全)
- spark连接
要想两个RDD进行连接,那么这两个rdd的数据格式,必须是k-v键值对的,其中的k就是关联的条件,也就是sql中的on连接条件。
假设,RDD1的类型[K, V], RDD2的类型[K, W]
- 内连接
val joinedRDD:RDD[(K, (V, W))] = rdd1.join(rdd2) - 左外连接
val leftJoinedRDD:RDD[(K, (V, Option[W]))] = rdd1.leftOuterJoin(rdd2) - 右外连接
val rightJoinedRDD:RDD[(K, (Option[V], W))] = rdd1.rightOuterJoin(rdd2) - 全连接
val fullJoinedRDD:RDD[(K, (Option[V], Option[W]))] = rdd1.fullOuterJoin(rdd2)
def join(sc: SparkContext): Unit = {
//sid, name, age, gender
val stuRDD = sc.parallelize(List(
"1,张三,23,male",
"2,李四,24,male",
"3,王五,25,female",
"4,赵六,26,male",
"5,周七,27,ladyboy"
))
//sid, course, score
val scoreRDD = sc.parallelize(List(
"1,math,98",
"2,chinese,61",
"3,english,69",
"4,math,30",
"6,chinese,77"
))
//将数据转换为RDD格式
val sid2InfoRDD: RDD[(Int, String)] = stuRDD.map(line => {
val index = line.indexOf(",")
val sid = line.substring(0, index).toInt
val baseInfo = line.substring(index + 1)
(sid, baseInfo)
})
val sid2ScoreRDD: RDD[(Int, String)] = scoreRDD.map(line => {
val index = line.indexOf(",")
val sid = line.substring(0, index).toInt
val scoreInfo = line.substring(index + 1)
(sid, scoreInfo)
})
//内连接
println("----------------inner-join------------------------")
val sid2FullInfo: RDD[(Int, (String, String))] = sid2InfoRDD.join(sid2ScoreRDD)
sid2FullInfo.foreach(t => {
println(s"sid:${t._1}, baseInfo:${t._2._1}, scoreInfo:${t._2._2}")
})
//几种输出方式
println("-----------")
sid2FullInfo.foreach { case (sid, (baseInfo, scoreInfo)) => {
println(s"sid:${sid}, baseInfo:${baseInfo}, scoreInfo:${scoreInfo}")
}
}
println("-----------")
sid2FullInfo.foreach(t => t match {
case (sid, (baseInfo, scoreInfo)) => {
println(s"sid:${sid}, baseInfo:${baseInfo}, scoreInfo:${scoreInfo}")
}
})
//左外连接
println("----------------left-outer-join------------------------")
//查询所有信息,因为右边的字段可能为null所以用Option
val leftJoinedRDD: RDD[(Int, (String, Option[String]))] = sid2InfoRDD.leftOuterJoin(sid2ScoreRDD)
leftJoinedRDD.foreach { case (sid, (baseInfo, optionScore)) => {
println(s"sid:${sid}, baseInfo:${baseInfo}, scoreInfo:${optionScore.getOrElse("null")}")
}
}
//右外连接
println("----------------right-outer-join------------------------")
//查询有考试的学生信息
val rightJoinedRDD: RDD[(Int, (Option[String], String))] = sid2InfoRDD.rightOuterJoin(sid2ScoreRDD)
rightJoinedRDD.foreach { case (sid, (baseInfo, scoreInfo)) => {
println(s"sid:${sid}, baseInfo:${baseInfo.getOrElse("null")}, scoreInfo:${scoreInfo}")
}
}
//全连接
println("----------------full-outer-join------------------------")
//所有
val fullJoinedRDD: RDD[(Int, (Option[String], Option[String]))] = sid2InfoRDD.fullOuterJoin(sid2ScoreRDD)
fullJoinedRDD.foreach { case (sid, (baseInfo, scoreInfo)) => {
println(s"sid:${sid}, baseInfo:${baseInfo.getOrElse("null")}, scoreInfo:${scoreInfo.getOrElse("null")}")
}
}
}7.groupByKey
原始rdd的类型时[(K, V)]
rdd.groupByKey(),按照key进行分组,那必然其结果就肯定[(K, Iterable[V])],是一个shuffle dependency宽依赖shuffle操作,但是这个groupByKe服务器托管网y不建议在工作过程中使用,除非非要用,因为groupByKey没有本地预聚合,性能较差,一般我们能用下面的reduceByKey或者combineByKey或者aggregateByKey代替就尽量代替。
//使用groupByKey对不同地区的学生进行分组
def gbk(sc: SparkContext): Unit = {
val stuRDD = sc.parallelize(List(
"张三,23,bj",
"李四,24,sh",
"王五,25,sz",
"赵六,26,sh",
"周七,27,bj",
"李八,28,sh"
))
val class2Info: RDD[(String, String)] = stuRDD.map(line => {
val index = line.lastIndexOf(",")
val cls = line.substring(index + 1)
val info = line.substring(0, index)
(cls, info)
})
//分组
val class2Infos: RDD[(String, Iterable[String])] = class2Info.groupByKey()
class2Infos.foreach { case (cls, stus) => {
println(s"class: ${cls}, stus: ${stus}")
}
}
}8.reduceByKey
rdd.reduceByKey(func:(V, V) => V):RDD[(K, V)] ====>在scala集合中学习过一个reduce(func:(W, W) => W)操作,是一个聚合操作,这里的reduceByKey按照就理解为在groupByKey(按照key进行分组[(K, Iterable[V])])的基础上,对每一个key对应的Iterable[V]执行reduce操作。
同时reduceByKey操作会有一个本地预聚合的操作,所以是一个shuffle dependency宽依赖shuffle操作。
//使用reduceByKey对不同地区的学生进行分组
def rbk(sc: SparkContext): Unit = {
val stuRDD = sc.parallelize(List(
"张三,23,bj",
"李四,24,sh",
"王五,25,sz",
"赵六,26,sh",
"周七,27,bj",
"李八,28,sh"
))
println(stuRDD)
val class2Info: RDD[(String, String)] = stuRDD.map(line => {
val index = line.lastIndexOf(",")
val cls = line.substring(index + 1)
val info = line.substring(0, index)
(cls, info)
})
val cls2InfoStr: RDD[(String, String)] = class2Info.reduceByKey((infos, info) => s"${infos}|${info}")
cls2InfoStr.map { case (cls, info) => {
(cls, info.split("\|").toIterable)
}
}.foreach { case (cls, stus) => {
println(s"class: ${cls}, stus: ${stus}")
}
}
}9.combineByKey
这是spark最底层的聚合算子之一,按照key进行各种各样的聚合操作,spark提供的很多高阶算子,都是基于该算子实现的。
def combineByKey[C](
createCombiner: V => C,
mergeValue: (C, V) => C,
mergeCombiners: (C, C) => C): RDD[(K, C)] = {
......
}上述源码便是combineByKey的定义,是将一个类型为[(K, V)]的RDD聚合转化为[(K, C)]的类型,也就是按照K来进行聚合。这里的V是聚合前的类型,C聚合之后的类型。
如何理解聚合函数?切入点就是如何理解分布式计算?总—>分—>总
createCombiner: V => C, 相同的Key在分区中会调用一次该函数,用于创建聚合之后的类型,为了和后续Key相同的数据进行聚合
mergeValue: (C, V) => C, 在相同分区中基于上述createCombiner基础之上的局部聚合
mergeCombiners: (C, C) => C) 将每个分区中相同key聚合的结果在分区间进行全局聚合
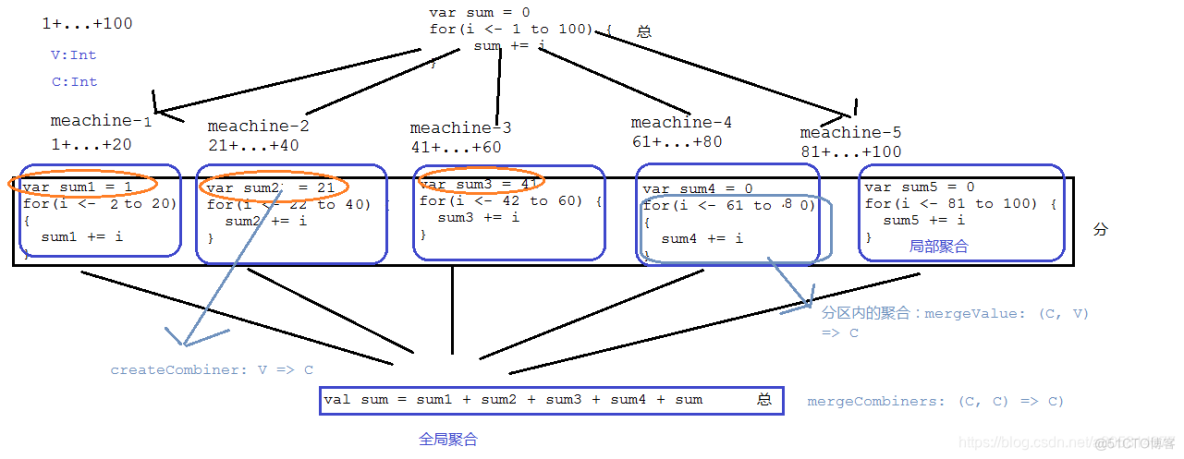
所以combineByKey就是分布式计算。
CombineByKey模拟groupByKey
package blog
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.mutable.ArrayBuffer
/**
*CombineByKey模拟groupByKey
*/
object CombineByKey2GroupByKey {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setAppName(s"${CombineByKey2GroupByKey.getClass.getSimpleName}")
.setMaster("local[*]")
val sc = new SparkContext(conf)
cbk2Gbk(sc)
sc.stop()
}
def cbk2Gbk(sc: SparkContext): Unit = {
val stuRDD = sc.parallelize(List(
"张三,23,bj",
"李四,24,sh",
"王五,25,sz",
"赵六,26,sh",
"周七,27,bj",
"李八,28,sh"
))
val class2Info: RDD[(String, String)] = stuRDD.map(line => {
val index = line.lastIndexOf(",")
val cls = line.substring(index + 1)
val info = line.substring(0, index)
(cls, line)
})
class2Info.saveAsTextFile("file:///F:/test/sparkout")
val cbk2Gbk: RDD[(String, ArrayBuffer[String])] = class2Info.combineByKey(createCombiner, mergeValue, mergeCombiners)
cbk2Gbk.foreach { case (cls, stus) => {
println(s"cls: ${cls}, stus: " + stus)
}
}
}
//分区内的初始化操作
def createCombiner(info: String): ArrayBuffer[String] = {
println("----------createCombiner------ " + info)
ArrayBuffer[String](info)
}
//分区内的局部聚合
def mergeValue(ab: ArrayBuffer[String], info: String): ArrayBuffer[String] = {
println("--mergeValue ----- " + ab + ">>> " + info)
ab.append(info)
ab
}
//分区间的聚合
def mergeCombiners(ab: ArrayBuffer[String], ab1: ArrayBuffer[String]): ArrayBuffer[String] = {
println("--mergeCombiners ----- " + ab + ">>> " + ab1)
ab.++(ab1)
}
}CombineByKey模拟reduceByKey
package blog
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
*CombineByKey模拟reduceByKey
*/
object CombineByKey2ReduceByKey {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setAppName(s"${CombineByKey2ReduceByKey.getClass.getSimpleName}")
.setMaster("local[*]")
val sc = new SparkContext(conf)
cbk2Rbk(sc)
sc.stop()
}
def cbk2Rbk(sc: SparkContext): Unit = {
val stuRDD = sc.parallelize(List(
"张三,23,bj",
"李四,24,sh",
"王五,25,sz",
"赵六,26,sh",
"周七,27,bj",
"李八,28,sh"
))
val class2Count: RDD[(String, Int)] = stuRDD.map(line => {
val index = line.lastIndexOf(",")
val cls = line.substring(index + 1)
(cls, 1)
})
class2Count.combineByKey((num: Int) => num,
(mn: Int, m: Int) => mn + m,
(sum: Int, sumi: Int) => sum + sumi)
.foreach(println)
}
def createCombiner(num: Int) = num
def mergeValue(mergeNum: Int, num: Int): Int = mergeNum + num
def mergeCombiners(sum: Int, sumi: Int) = sum + sumi
}10.aggregateByKey
AggregateByKey模拟reduceByKey
package blog
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.mutable.ArrayBuffer
/**
*
*/
//AggregateByKey模拟reduceByKey
object AggregateByKey2ReduceByKey {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setAppName(s"${AggregateByKey2ReduceByKey.getClass.getSimpleName}")
.setMaster("local[2]")
val sc = new SparkContext(conf)
abk2gbk(sc)
//abk2rbk(sc)
sc.stop()
}
def abk2gbk(sc: SparkContext): Unit = {
val stuRDD = sc.parallelize(List(
"张三,23,bj",
"李四,24,sh",
"王五,25,sz",
"赵六,26,sh",
"周七,27,bj",
"李八,28,sh"
))
val class2Info: RDD[(String, String)] = stuRDD.map(line => {
val index = line.lastIndexOf(",")
val cls = line.substring(index + 1)
val info = line.substring(0, index)
(cls, line)
})
class2Info.saveAsTextFile("file:///f:/test/gbk")
val cls2Infos: RDD[(String, ArrayBuffer[String])] = class2Info.aggregateByKey(ArrayBuffer[String]())(
(ab, info) => ab.+:(info),
(ab1, ab2) => ab1.++(ab2)
)
cls2Infos.foreach(println)
}
def abk2rbk(sc: SparkContext): Unit = {
val stuRDD = sc.parallelize(List(
"张三,23,bj",
"李四,24,sh",
"王五,25,sz",
"赵六,26,sh",
"周七,27,bj",
"李八,28,sh"
))
val class2Info: RDD[(String, Int)] = stuRDD.map(line => {
val index = line.lastIndexOf(",")
val cls = line.substring(index + 1)
(cls, 1)
})
class2Info
.aggregateByKey(0)(_ + _, _ + _)
.foreach(println)
}
}服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
