
在spark集群上跑一个程序首先保证下面进程开启
- zookeeper
- hdfs
- spark
首先是父类的依赖
2.11.8
2.2.2
2.7.6
spark-core-study
spark-common
junit
junit
4.12
org.apache.spark
spark-core_2.11
${spark.version}
org.apache.spark
spark-sql_2.11
${spark.version}
org.apache.spark
spark-streaming_2.11
${spark.version}
然后是子类的依赖
org.apache.spark
spark-core_2.11
provided
WordCount
package blog
import org.apache.log4j.{Level, Logger}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* WordCount
*/
object WordCount {
def main(args: Array[String]): Unit = {
//提示语,如果没有参数就报错,直接退出jvm
if (args == null || args.length
|input: input file path
""".stripMargin
//stripMargin是用来分行显示的
)
System.exit(-1)
}
val Array(input) = args
//打印需要的日志
Logger.getLogger("org.apache.hadoop").setLevel(Level.INFO)
Logger.getLogger("org.apache.spark").setLevel(Level.INFO)
Logger.getLogger("org.spark_project").setLevel(Level.INFO)
val conf = new SparkConf()
//这里名字可以随便去
.setAppName("WordCount")
//加上下面这句话就是在单个节点跑,Web UI上不会有显示
//.setMaster("local[*]")
//SparkContext为spark的入口
val sc = new SparkContext(conf)
//获取每一行
val lines: RDD[String] = sc.textFile(input)
//这里我们可以看一下spark将文件分成了几个区
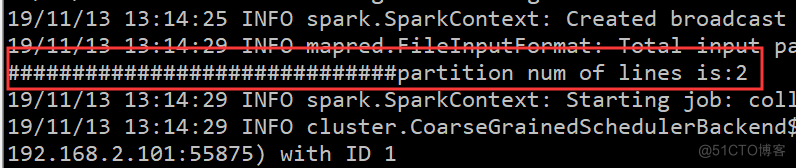
println("##############################partition num of lines is:" + lines.getNumPartitions)
//flatMap进行过滤,s+表示切到空格以及多个空格
val words: RDD[String] = lines.flatMap(line => line.split("s+"))
//map端直接调用
val pairs: RDD[(String, Int)] = words.map(word => count(word))
//将出现多次的结果在reduce端相加
val retRDD: RDD[(String, Int)] = pairs.reduceByKey((v1, v2) => v1 + v2)
//控制台打印
retRDD
.collect() //
.foreach(println)
sc.stop()
}
//默认出现一次的单词为word, 1
def count(word: String): (String, Int) = (word, 1)
}接着开始打jar包,我这里使用的是idea,点击左上角的File,选择Project Structure
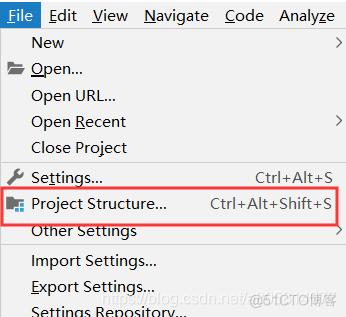
然后创建一个空的jar
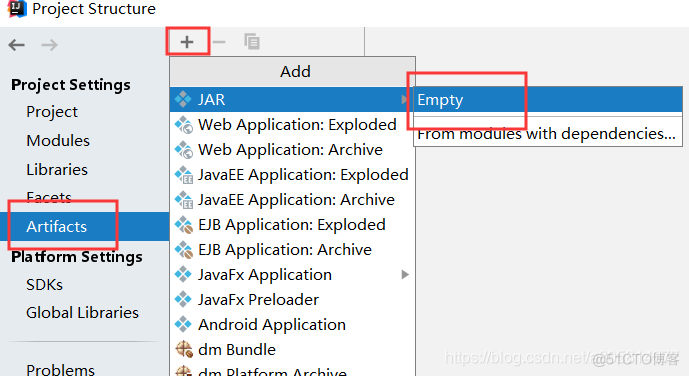
给jar包起一个名

选中要打包的代码

添加到左边去,然后点击OK
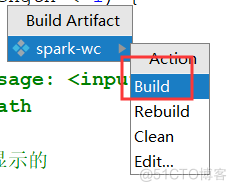
接着Build -> Bu服务器托管网ild Artifacts
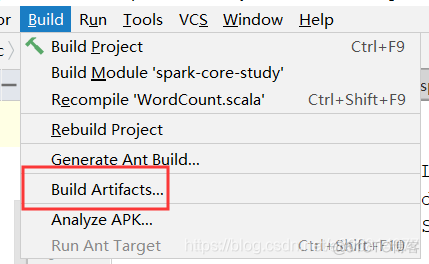
然后直接Bulid即可
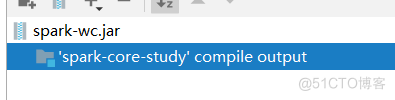
可以看到idea左边的窗口多出了一个out文件夹

然后打开文件所在位置
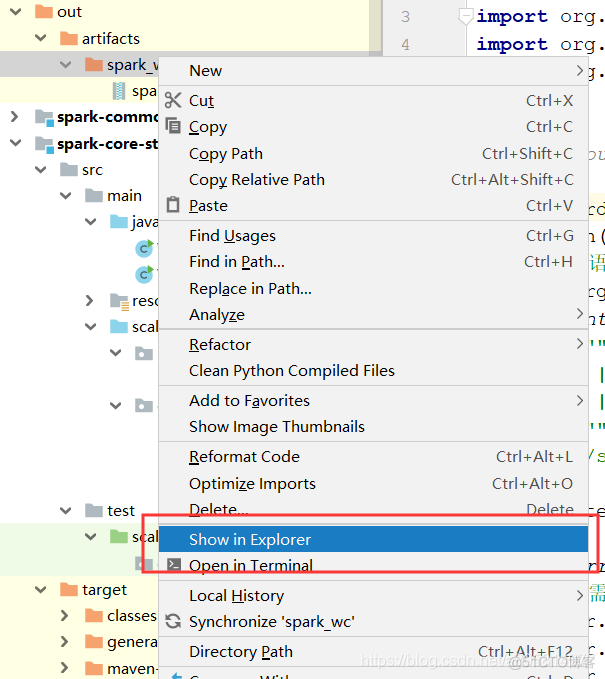
将文件上传到Linux,然后随便找一个文件夹创建一个脚本
vi spark-submit-wc-standalone.sh插入以下内容,文件的路径以及其他参数可以进行修改
#!/bin/sh
SPARK_HOME=/home/hadoop/apps/spark
${SPARK_HOME}/bin/spark-submit
--class blog.WordCount
--master spark://hadoop01:7077
--deploy-mode client
--total-executor-cores 2
--executor-cores 1
--executor-memory 600M
/home/hadoop/jars/spark/spark-wc.jar
hdfs://bd服务器托管网1906/data/spark/hello.txt这是文件内容,一定要保证hdfs上有这个文件
hello you
hello you
hello me
hello you
hello you
hello me
This page outlines the steps for getting a Storm cluster up and running如果没有的话可以上传一下
hdfs dfs -put hello.txt /data/spark/hello.txt然后在当前目录运行脚本
./spark-submit-wc-standalone.sh如果出现了权限不允许的错误,运行以下命令再运行脚本,如果没有可忽略
chmod 777 ./spark-submit-wc-standalone.sh成功输出结果

我们可以访问一下spark的web页面http://hadoop01:8080
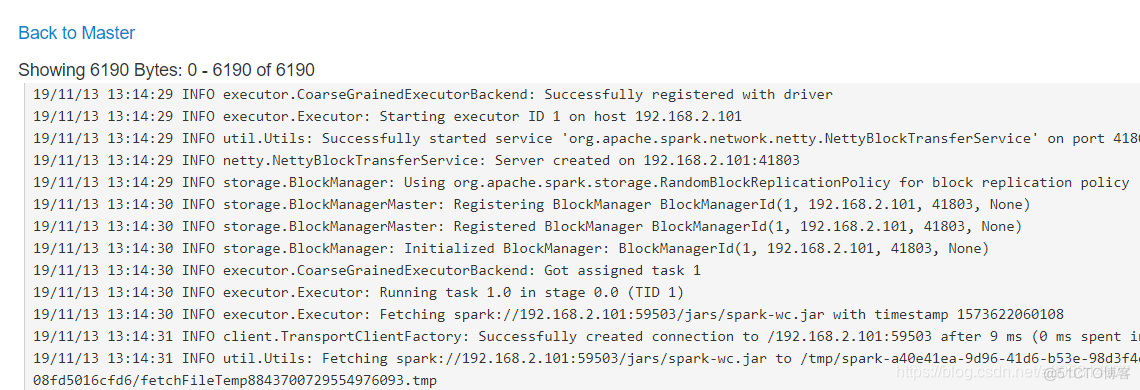
可以看到Completed Applications有记录

点进去,在stderr中可以看到详细信息
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
欢迎使用Markdown编辑器写博客 本Markdown编辑器使用StackEdit修改而来,用它写博客,将会带来全新的体验哦: Markdown和扩展Markdown简洁的语法 代码块高亮 图片链接和图片上传 LaTex数学公式 UML序列图和流程图 离线写…
