
一、Spark 框架概述
1.1 spark是什么
Apache Spark
是用于
大规模数据
(
large-scala data
)处理的
统一(
unified
)分析引擎
。
是用于
大规模数据
(
large-scala data
)处理的
统一(
unified
)分析引擎
。

Spark 借鉴了 MapReduce 思想发展而来,保留了其
分布式并行计算的优点
并改进了其明显的缺陷。让中间数据存储在内存中提高了运行速度、并提供丰富的操作数据的API提高了开发速度。
分布式并行计算的优点
并改进了其明显的缺陷。让中间数据存储在内存中提高了运行速度、并提供丰富的操作数据的API提高了开发速度。
Spark的适用面非常广泛,所以,被称之为 统一的(适用面广)的分析引擎(数据处理)
1.2 spark VS Hadoop
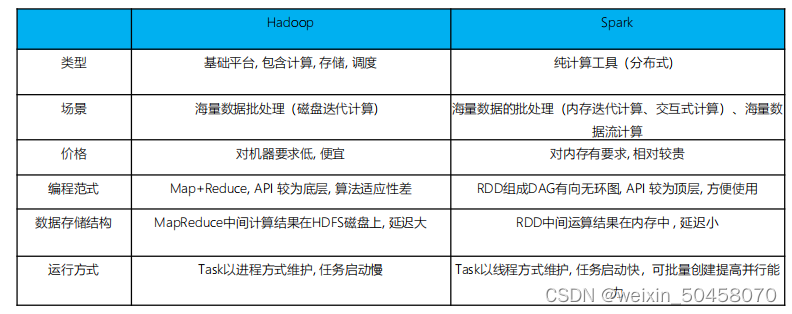
尽管Spark相对于Hadoop而言具有较大优势,但Spark并不能完全替代Hadoop
- 在计算层面,Spark相比较MR(MapReduce)有巨大的性能优势,但至今仍有许多计算工具基于MR构架,比如非常成熟的Hive
- Spark仅做计算,而Hadoop生态圈不仅有计算(MR)也有存储(HDFS)和资源管理调度(YARN),HDFS和YARN仍是许多大数据 体系的核心架构
Hadoop的基服务器托管网于进程的计算和Spark基于线程方式优缺点?
Hadoop中的MR中每个map/reduce task都是一个java进程方式运行,好处在于
进程之间是互相独立的,每个task独享进程资源,没有互相干扰,监控方便,但是问题在于task之间不方便共享数据,执行效率比较低。
比如多个map task读取不同数据源文件需要将数据源加 载到每个map task中,造成重复加服务器托管网载和浪费内存。而基于线程的方式计算是为了数据共享和提高执行效率,Spark采用了线程的最小的执行 单位,但缺点是
进程之间是互相独立的,每个task独享进程资源,没有互相干扰,监控方便,但是问题在于task之间不方便共享数据,执行效率比较低。
比如多个map task读取不同数据源文件需要将数据源加 载到每个map task中,造成重复加服务器托管网载和浪费内存。而基于线程的方式计算是为了数据共享和提高执行效率,Spark采用了线程的最小的执行 单位,但缺点是
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
1. 拉取代码到本地 git clone https://github.com/apache/doris.git 2. 参考Doris的文档,但别全信(信了服务器托管网你就上当了) 参考第一篇 https://doris.apache.org/zh-CN/co…
