
性能优化是一个很有趣的探索方向,将耗时耗资源的查询优化下来也是一件很有成就感的事情,但既然编程是一种沟通手段,那每一个数据开发者就都有义务保证写出的代码逻辑清晰,具有很好的可读性。
目录
引子
小试牛刀
答案
引言
表的设计
名字及含义
属性和列
SQL规范
注释
缩进
空格
大小写
逗号
通配符
SQL方法
数据库函数
连接
from子句
引子
小试牛刀
下面九个图形分别对应数字1-9
1 2 3 4
5 6 7 8 9
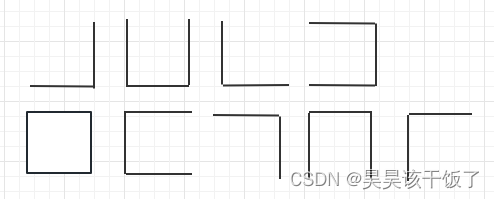
给大家一分钟的时间尝试能否记住并将他们按照奇偶分开默写出来
1、3、5、7、9、2、4、6、8
注意!下滑有答案!想思考一下的谨慎!
注意!下滑有答案!想思考一下的谨慎!
注意!下滑有答案!想思考一下的谨慎!
注意!下滑有答案!想思考一下的谨慎!
注意!下滑有答案!想思考一下的谨慎!
注意!下滑有答案!想思考一下的谨慎!
注意!下滑有答案!想思考一下的谨慎!
注意!下滑有答案!想思考一下的谨慎!
注意!下滑有答案!想思考一下的谨慎!
注意!下滑有答案!想思考一下的谨慎!
注意!下滑有答案!想思考一下的谨慎!
注意!下滑有答案!想思考一下的谨慎!
如果正在尝试记忆就先不要下滑,下面就是答案。
当然 这组数字图形大概率不那么好记
但是如果换一种方式我保证你只用十秒就理解掌握并且记住他了。
答案就在下面。。
————– 分割线 —————
答案
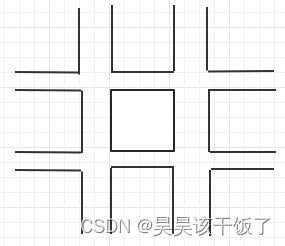
如图,九宫格对应1-9辅助记忆即可,选择一种已经被大众接受且规范的做法,无疑是良好的开端。
引言
如何改变 能跑起来就行、效率才是一切 这种偏执的观念,认真的思考如何写出任何人看一眼就觉得简单明了的代码,追求使用大多数人所能理解的常识和模式,确立统一的编程风格。
事实上,数据库领域的发展并没有到开始关注编程风格的阶段,SQL作为一种非过程语言,受到的重视也远远不够,对于SQL这门语言也很少有人深入的研究。但随着数据时代的到来,大家逐渐注意到了SQL的强大实力,同时代码也会变得越来越复杂,数据工程师的SQL代码风格也一定会在不久的将来被明确。
表的设计
名字及含义
关系数据库在各类系统中获得广泛支持的最重要的原因,就在于它放弃了 地址 这一无意义的概念。放弃地址,留下了 名称。
对于列、表、索引,以及约束,命名时都请做到名副其实。尽量不要使用A、aa,或者idx_123 这样无意义的符号。特别需要注意的是,如果没有为索引和约束显式地指定名称,Database 就会自动为之分配随机的名称,这也是要注意避免的。
命名时允许的字符有以下3种:
- 英文字母
- 阿拉伯数字
- 下划线 _
除此之外,各个数据库实现中可能还加入了$、#、@等特殊符号,以及汉字这样2字节的文字,但个人认为最好不要使用。因为这样写出的代码可移植性不好,而且容易隐藏Bug。还有,标准 SQL 中规定名称的第一个字符应该是英文字母,这一点我们也应该遵守。
属性和列
使用有意义的列名:
- 列名应该反映其存储的数据内容,使用清晰、描述性的名称,避免使用含糊或缩写的名称。
- 遵循一致的命名约定,如使用下划线或驼峰命名法。
使用适当的数据类型:
- 选择最合适的数据类型来存储数据,以节省空间并确保数据的准确性。例如,使用整数类型存储整数数据,使用日期/时间类型存储日期和时间。
- 避免过度使用通用数服务器托管网据类型,如使用TEXT存储日期,这会导致性能问题。
使用合适的默认值:
- 为列设置合适的默认值,以便在插入新记录时提供默认值,或者在未指定值时使用默认值。
SQL规范
注释
注释是编程风格中一个比较有争议的话题。有些人极力主张必须要添加注释,相反也有人认为注释只会使代码的可读性降低,因此努力方向应该是把代码写得不需要注释也能看懂。
不管其他语言怎么样,就SQL而论,最好还是写注释。 这样说主要有两个原因:一个是SQL是声明式语言,即使表达同样的处理过程,逻辑仍然比面向过程语言凝练得多;另一个是,SQL 很难进行分步的执行调试。分析代码时主要需要进行桌面调试。
注释的写法主要有以下两种:
-- 单行注释
-- 使用表t1
select * from t1-- 多行注释
/*
一大段注释
使用表t1查询
*/
select * from t1注释也可以穿插在代码中或者代码后:
select t1.customer_id, t3.name
from(
select t1.customer_id as customer_id, t3.name as name, t1.date_mouth, sum(t1.quantity * t2.price) as amount
-- 下面是一次子查询
from(
select customer_id, product_id, substr(order_date, 0, 7) as date_mouth, quantity
from Orders
)t1 -- 作为底表向后进行左关联
left join(
select product_id, price from Product
)t2 on t1.product_id = t2.product_id
left join(
select customer_id, name from Customers
)t3 on t1.customer_id = t3.customer_id
group by t1.customer_id, t3.name, t1.date_mouth
having amount >= 100
)a
having count(1) = 2缩进
代码难以阅读的原因里,也许排在第一位的是没有进行缩进(排在第二位的是没有对长代码划分模块,所有的都揉在一起)
对于初学者,他们不了解缩进的重要性,写出来的代码每一行都从行首开始。如果是练习用的小的程序,即使不缩进也不至于带来混乱,因此这样也没什么不可以。但是对于专业的工程师来说,如果写代码没有缩进意识就不能容忍了。
下面是好和坏的示例:
-- bad
select t1.customer_id as customer_id, t3.name as name, t1.date_mouth, sum(t1.quantity * t2.price) as amount
from(
select customer_id, product_id, substr(order_date, 0, 7) as date_mouth, quantity
from Orders
)t1
left join(
select product_id, price
from Product
)t2
on t1.product_id = t2.product_id
left join(
select customer_id, name
from Customers
)t3
on t1.customer_id = t3.customer_id
group by t1.customer_id, t3.name, t1.date_mouth
having amount >= 100
-- good
select t1.customer_id as customer_id,
t3.name as name,
t1.date_mouth,
sum(t1.quantity * t2.price) as amount
from(
select customer_id,
product_id,
substr(order_date, 1, 7) as date_mouth,
quantity
from Orders
)t1
left join(
select product_id,
price
from Product
)t2 on t1.product_id = t2.product_id
left join(
select customer_id,
name
from Customers
)t3 on t1.customer_id = t3.customer_id
group by t1.customer_id,
t3.name,
t1.date_mouth
having amount >= 100在好的示范里,我们首先可以看到,子查询的代码缩进了一层。 请牢记这个规则。子查询这个名称的开头是“子”,这就说明它是低一层的逻辑。 然后,在SELECT 子句和 GROUP BY 子句中指定多列时,也需要缩进一层。缩进之后,“子句”的代码块就变得很清晰,更方便阅读。如果不想让代码的行数增加得太多,也可以每行写3列或5列,或者根据具体含义汇总多列进行换行。
空格
无论什么编程语言,适当的空格都会让代码变得更美好。这是一种约定俗成的习惯,当然如果不加空格也不会有任何问题。
# bad
select id,substr(order_date,1,7) as date_mouth,quantity
from Orders
# good
select id, substr(order_date, 1, 7) as date_mouth,quantity
from Orders大小写
这个也是约定俗成的规范,关键字一般全部大写,其他全部小写,如下:
SELECT col_1,
col. 1_2,
col_3,
COUNT (*)
FROM tbI_A
WHERE col_1 = 'a'
AND col_2 =
(SELECT MAX (col 12)
FROM tbI_B
WHERE col 3 =100)
GROUP BY col_1, col_ 2, co1_3 ; 逗号
这个各自有各自的看法,都是对的,分享一种个人习惯的:
select id
,name
,age
from Orders通配符
使用通配符 *服务器托管网 会将表的全部列选中,虽然在写法上方便了许多,但结果中也会包含很多不需要的咧,不但会降低代码的可读性,而且不利用需求的变更。
# good
select id, name, age from Orders
# bad
select * from OrdersSQL方法
SQL 是一种有多种方言的语言,各种数据库实现都为我们做了各种扩展(不管是好的还是坏的)。SQL 官方其实已经制定了标准语法,但是并没能做出多少推动统一的努力。关于这一点,也有一些历史原因。过去的标准SQL 很弱,并没有达到实用的程度,很多数据库厂商不得不自己扩展标准SQL中没有的功能。 但是,近年标准SQL 越来越完善,也越来越实用了。如果还继续使用各种数据库的方言进行编程,就会出现很难在PostgreSQL、Oracle、SQL Server、MySQL 这样的DBMS之间移植代码的情况,而且开发者换到不熟悉的 DBMS 后会很不习惯新的编程环境。 这些问题只需要稍微注意一下就可以避免,所以大家还是在日常开发中养成使用标准语法的习惯吧。
数据库函数
很多依赖数据库实现的函数都是转换函数或字符串处理函数。不要使用这些函数:
- DECODE(Oracle)
- IF(MySQL)
- NVL(Oracle)
- STUEF(SQLServer)
可以使用 CASE 表达式或者 COALESCE、NULLIF 等标准函数代替它们。此外,像 SIGN或 ABS、REPLACE 这些,虽然标准 SQL没有定义它们,但是几乎所有的数据库都实现了它们,所以使用一下也没关系。 让人头疼的是标准SQL中有定义,但是各数据库实现情况不同的功能。例如日期函数 EXTRACT,以及用于字符串连接的运算符“||”或者POSITION 函数。这些函数的使用频率都很高,但是请记住,使用它们会导致代码的可移植性变差。
连接
在SQL 的语法中,依赖数据库实现最严重的是连接语句。
标准SQL 中允许省略关键字OUTER,但是这个关键字便于我们理解它是外连接而非内连接,所以还是写上吧。
SELECT *
FROM FOO F INNER JOIN Bar B
ON F.state = B.state
WHERE F.city='东京;from子句
优先从from开始写你的SQL吧 —- 如果他很大的话
原是 SELECT 子句是SQL 语句中最后执行的部分,写的时候根本没有必要太在意。
SQL 中各部分的执行顺序是:FROM – WHERE – GROUP BY – HAVING – SELECT(-ORDER BY)。严格地说,ORDER BY并不是SQL 语句的一部分,因此可以排除在外。这样一来,SELECT就是最后才被执行的部分了。
因此,如果需要写很复杂的SQL语句,可以考虑按照执行顺序从 FROM 子句开始写,这样添加逻辑时更加自然。即使不知道在 SELECT 子句里写什么,也肯定知道应该在FROM 子句中写些什么(如果不知道,那么说明表的结构还没有确定,因此应该先完成表的设计,然后再考虑 SQL 语句)。

最后的最后,还是那句话,既然编程是一种沟通手段,那每一个数据开发者就都有义务保证写出的代码逻辑清晰,具有很好的可读性。
————–
2023.10.07
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
