
全文链接:http://tecdat.cn/?p=32118
原文出处:拓端数据部落公众号
假如你有一个购物类的网站,那么你如何给你的客户来推荐产品呢?这个功能在很多电商类网站都有,那么,通过SQL Server Analysis Services的数据挖掘功能,你也可以轻松的来构建类似的功能。
将分为三个部分来演示如何实现这个功能。
此篇文章演示了如何帮助客户使用SQL Server Analysis Services基于此问题来构建简单的挖掘模型。
步骤
准备工作:数据.xls 数据导入数据库中。


准备工作:数据.xls 数据导入数据库中。
在相应数据库中找到对应的数据
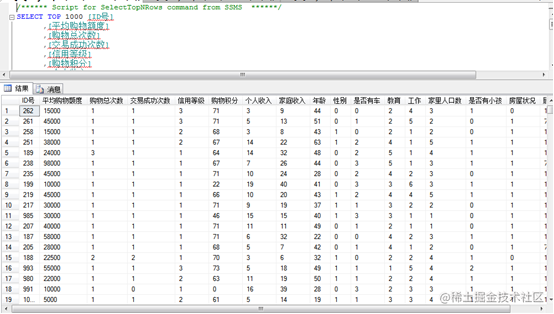
(1) 打开visual studio,新建项目,选择商业智能项目,analysis services项目
将data-mining数据库中的数据导入数据源

在可用对象中,将要分析数据所在表添加到包含的对象中,继续下一步
在解决方案资源管理器中,右键单击挖掘结构,选择新建挖掘结构

选择microsoft 决策树,继续下一步
设置测试集和训练集
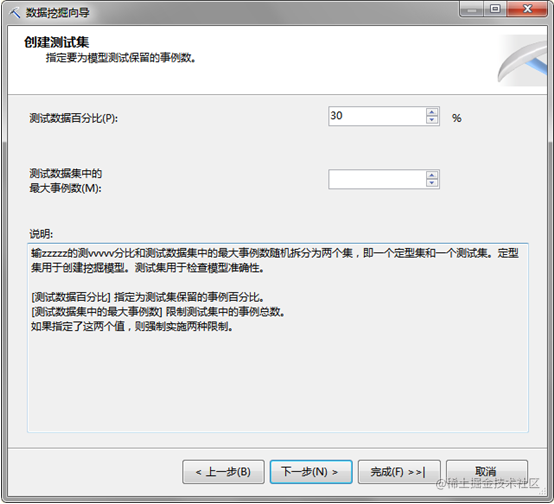
勾选允许钻取,完成
然后对模型进行部署,继而进行挖掘(点击运行)
决策树模型
以下我们对电商购物网站的用户的信誉等级进行预测,使用其他用户的特征属性对其进行预测分类。建立如下的决策树模型。
从决策树模型的结果来看,

树一共有5个分支。其中重要节点分别为购物积分、家里人口数、居住面积、居住面积等。
从图中可以看到购物积分越高的用户,决策树得到的用户信誉等级越高。同时家里人口数越多,则信誉等级也越高。说明购物积分直接影响着信誉等级。一般购物次数越多则买家的信誉越高。同时家里人口数越多,则该用户在网上购物的开支越多。因此会导致网上购物越多,最后导致信誉增加。

然后可以看到依赖网络。依赖网络图是指预测变量和其他变量直接的依赖性。从图中可以看到在用户属性中,几个属性会影响信用等级,包括购物积分、次数、居住面积以及人口数量。

聚类
从聚类结果可以看到,聚类将所有用户分成了10个信用级别。
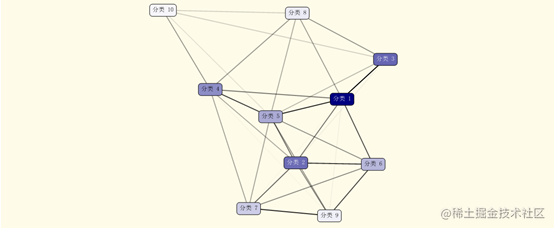
从不同类别的依赖图可以看到,类别10、4、8、5之间具有较强的相关关系。说明这几个类别中的信用级别是类似的。下面可以具体看下每个类别中的各个属性的分布的比例。
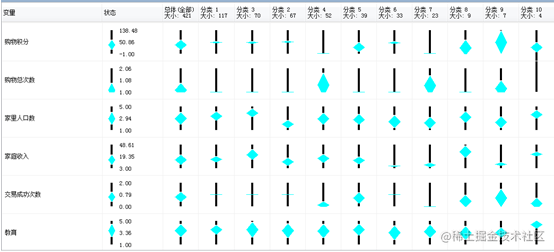
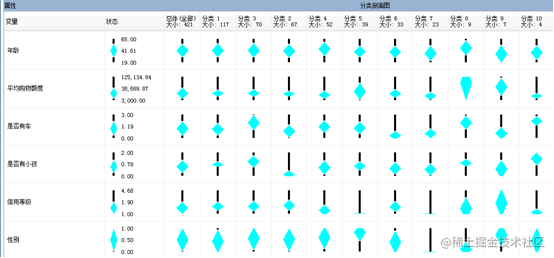
从上图可以看到不同类别的购物积分是不同的。
总的来看,相对来说,第4和7类别的购物积分最小的,其他几个类别中积分较高,因此可以认为这些类别中的用户的信用级别较高。同时可以看到这些类别的其他信息,这类用户的月收入较低,购物次数也较小。同时可以看到,这类用户大多的交易成功也较少。另一方面,可以看到低购物积分用户中 ,家庭人口数也较小。

从每个类别的倾向程度来看,购物总次数多的用户交易成功次数也高。从另一方面来看,月收入较高的用户,倾向于是非分类1的用户,也就是它们的信用等级较好。同时可以看到,户交易成功次数多喝购物积分高的用户倾向于非分类1的用户。说明用户的信用等级相对较高。另一方面,可以看到拥有房屋的用户的交易成功次数 电商网站购物次数反而低于没有房屋的用户,可能是因为没有房屋的用户年龄段较低,因此更倾向于网络购物。
然后建立关联规则挖掘模型
运行关联规则 得到以下重要的关联规则

关联规则就是发现数据集中相互有关联的项目。它已经成为数据挖掘领域中具有重要影响的一种算法。也是数据挖掘领域的一个重要分支。最近几年已经被广泛的应用。在电子商务领域,关联规则技术主要用于物品链接页面等的推荐,它只需要购物记录的数据即可,而不需要过多的商品信息,通过关联规则可以发现用户的一些常见的购物模式和购物规律。找出用户通常会一起购买的商品。从而对用户进行推荐和挖掘

最受欢迎的见解
1.PYTHON用户流失数据挖掘:建立逻辑回归、XGBOOST、随机森林、决策树、支持向量机、朴素贝叶斯模型和KMEANS聚类用户画像
2.R语言基于树的方法:决策树,随机森林
3.python中使用scikit-learn和pandas决策树
4.机器学习:在SAS中运行随机森林数据分析报告
5.R语言用随机森林和文本挖掘提高航空公司客户满意度
6.机器学习助推快时尚精准销售时间序列
7.用机器学习识别不断变化的股市状况——隐马尔可夫模型的应用
8.python机器学习:推荐系统实现(以矩阵分解来协同过滤)
9.python中用pytorch机器学习分类预测银行客户流失
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
