
神经网络初步
以scikit-leran鸢尾花为例
通过scikit-learn库自带的鸢尾花数据集 来测试数据的读入
from sklearn import datasets
from pandas import DataFrame
import pandas as pd
x_data = datasets.load_iris().data # .data返回iris数据集所有输入特征
y_data = datasets.load_iris().target # .target返回iris数据集所有标签
print("x_data from datasets: n", x_data)
print("y_data from datasets: n", y_data)
x_data = DataFrame(x_data, columns=['花萼长度', '花萼宽度', '花瓣长度', '花瓣宽度']) # 为表格增加行索引(左侧)和列标服务器托管网签(上方)
pd.set_option('display.unicode.east_asian_width', True) # 设置列名对齐
print("x_data add in服务器托管网dex: n", x_data)
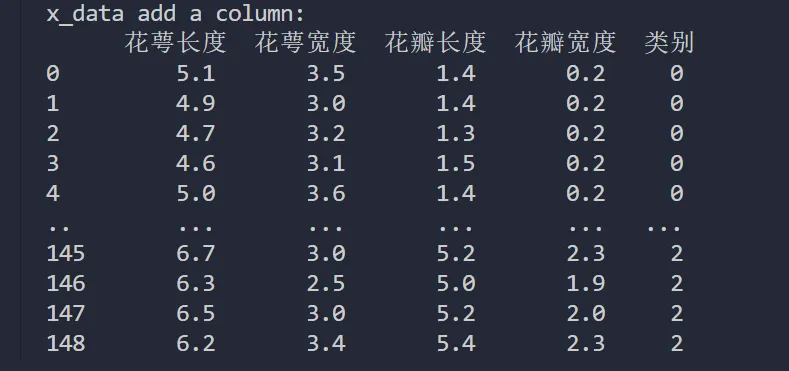
x_data['类别'] = y_data # 新加一列,列标签为‘类别’,数据为y_data
print("x_data add a column: n", x_data)
#类型维度不确定时,建议用print函数打印出来确认效果
使用pandas包中的dataframe类来完成数据的表格输出
可以自定义行,列的索引名
打印结果:
网络构造流程
将数据集完成分类:训练集-测试集 并将输入特征与标签进行配对
每次读入一个batch进行训练 嵌套循环迭代 显示当前的loss与acc

数据集预处理
每次喂入神经网络模型的数据单位为batch
每个batch包含的数据组数可以自定义
from sklearn import datasets
from pandas import DataFrame
import pandas as pd
import numpy as np
#数据集的读入:
x_data = datasets.load_iris().data # .data返回iris数据集所有输入特征
y_data = datasets.load_iris().target # .target返回iris数据集所有标签
# 随机打乱数据:
# seed: 随机数种子,是一个整数,当设置之后,每次生成的随机数都一样
np.random.seed(116) # 使用相同的seed,保证输入特征和标签一一对应
np.random.shuffle(x_data) #将输入特征以seed进行随机打乱
np.random.seed(116)
np.random.shuffle(y_data) #将数据标签以seed进行随机打乱
tf.random.set_seed(116)
#将数据集分为训练集和测试集:
#数据集和测试集必须没有交集
x_train = x_data[:-30] #训练集为前120行
y_train = y_data[:-30]
x_test = x_data[-30:] #测试集为后30行
y_test = y_data[-30:]
#将特征与标签进行配对,并且每次只喂入模型一小撮数据
train_db = tf.data.Dataset.from_tensor_slices((x_train, y_train))
train_db = train_db.batch(32)
test_db = tf.data.Dataset.from_tensor_slices((x_test, y_test))
test_db = test_db.batch(32)
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
首先要下载并且安装git 下载地址Git (git-scm.com) 安装傻瓜式安装 目录 一.设置用户信息 二.为常用指令配置别名编辑 三.获取本地仓库 1.要使用Git对我们的代码进行服务器托管网版本控制,首先需要获得本地仓库 四.基础操作指令 1.一次提…
