
torch分布式训练笔记
- 1. 数据并行(DistributedDataParallel)
- 2. 模型并行(单机多卡)
- 3. 混合并行(数据并行 + 模型并行/PipeLine并行)
1. 数据并行(DistributedDataParallel)
官方文档:DISTRIBUTED DATA PARALLEL
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
import torch.nn as nn
import torch.optim as optim
from torch.nn.parallel import DistributedDataParallel as DDP
def example(rank, world_size):
# create default process group
dist.init_process_group("gloo", rank=rank, world_size=world_size)
# create local model
model = nn.Linear(10, 10).to(rank)
# construct DDP model
ddp_model = DDP(model, device_ids=[rank])
# define loss function and optimizer
loss_fn = nn.MSELoss()
optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)
# forward pass
outputs = ddp_model(torch.randn(20, 10).to(rank))
labels = torch.randn(20, 10).to(rank)
# backward pass
loss_fn(outputs, labels).backward()
# update parameters
optimizer.step()
def main():
world_size = 2
mp.spawn(example,
args=(world_size,),
nprocs=world_size,
join=True)
if __name__=="__main__":
# Environment variables which need to be
# set when using c10d's default "env"
# initialization mode.
os.environ["MASTER_ADDR"] = "localhost"
os.environ["MASTER_PORT"] = "29500"
main()代码从上面链接的 torch 教程中拷贝来的。
上面代码有些注意的地方:
- 首先数据并行的基本方式就是多进程,即一个进程管理一张GPU卡。上面代码使用 torch.multiprocessing 发起多个进程,这个 python 的 multiprocessing 是类似的。
- mp.spawn 中,每个进程都运行 example 函数,但是传入的参数只有 world_size,而 example 函数却要求两个参数(rank, world_size),看起来少了一个 rank 参数,但实际运行中,example 可以得到 rank 参数,rank 表示当前的进程是管理的哪张卡。
- 开始一定要 init_process_group 一下,从传入的参数可以推测出,这句话是将每张卡上对应的进程(rank),一个 world_size 个进程放进一个进程组。这样做是 torch 内部,方便管理实现进程组中进程的通信呢。
数据并行原理很简单,流程至少包括:
- 将模型的副本拷贝到每张GPU卡上
- 每个GPU卡上更新一次参数后,梯度信息同步更新(All-Reduce)
看起来上面代码并没有“直观”的处理这两个问题。官网文档介绍了,DDP 是如何实现这两个流程的。
正如文档中介绍的那样,
ddp_model = DDP(model, device_ids=[rank])DDP的构造函数中把上面说的流程都做了。具体包括:
- broadcasts state_dict() from the process with rank 0 to all other processes in the group to make sure that all model replicas start from the exact same state.
- Then, each DDP process creates a local Reducer, which later will take care of the gradients synchronization during the backward pass.
此外,还特意说明了为了提高通信效率,是以“bucket”为单位进行通信。最基础的想法是,所有的卡都完成了整个模型的反向传播和梯度更新后,开始通信。但实际上每张卡可能效率不同,有的卡完成了全部梯度的更新,有的还没有。这样一些卡就需要等待,GPU利用率低。
文档中这张图做了很好的解释。这里假设模型只有四个参数,分成两个 bucket,反向传播时,bucket0中的两个参数的梯度信息完成更新后,两个进程就可以分别调用 allreduce 操作,完成梯度信息的通信和同步。而不必等到整个模型中所有的参数梯度信息都更新后再通信。
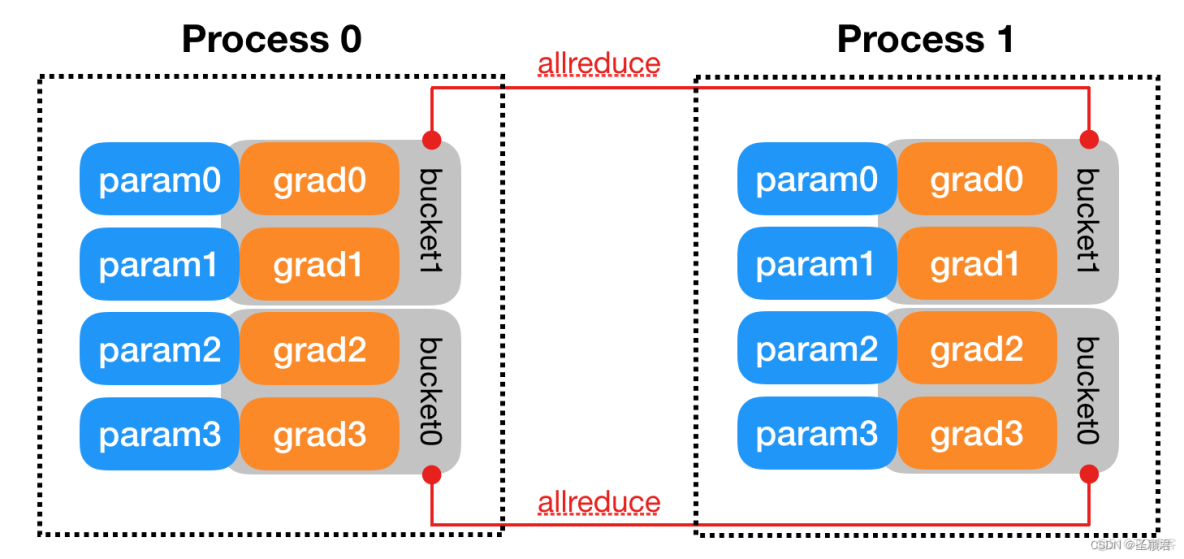
这样就可以 overlapping allreduce collectives with computations during backwards.提高性能。
文档最后介绍了 DDP 里面的实现构成,比如广播模型参数和梯度信息同步就使用了 ProcessGroup::broadcast() , ProcessGroup::allreduce() 这些 api。 这也是代码开始需要初始化进程组的原因。
其他:关于 forward 和 backwark 中更多细节,比如通信具体是如何触发的, hook 的实现,这些后续阅读代码细节时再做介绍。
2. 模型并行(单机多卡)
官方文档:SINGLE-MACHINE MODEL PARALLEL BEST PRACTICESBasic Usage
import torch
import torch.nn as nn
import torch.optim as optim
class ToyModel(nn.Module):
def __init__(self):
super(ToyModel, self).__init__()
self.net1 = torch.nn.Linear(10, 10).to('cuda:0')
self.relu = torch.nn.ReLU()
self.net2 = torch.nn.Linear(10, 5).to('cuda:1')
def forward(self, x):
x = self.relu(self.net1(x.to('cuda:0')))
return self.net2(x.to('cuda:1'))
model = ToyModel()
loss_fn = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.001)
optimizer.zero_grad()
outputs = model(torch.randn(20, 10))
labels = torch.randn(20, 5).to('cuda:1')
loss_fn(outputs, labels).backward()
optimizer.step()直观上看,这里最大区别是没有使用多进程,而是使用单进程管理多张卡。由于是在单机上,并不需要进程组中进程之间的通信,只需要将中间数据在多卡之间进行拷贝。
模型并行将模型不同的 layer 放在不同的卡上。如 init 函数, 中的 to(‘cuda: 0’)。
为啥中间的 relu 不写成 “torch.nn.Relu().to(‘cuda:0’) ” 呢。(当然这样写也是可以的,只不过没有任何作用),因为 relu 运行不需要权重数据。
模型具体来说可以理解为两个部分:拓扑结构(计算图/计算流程) + 权重(参数)
将模型的不同layer放在不同的卡上,本质是将模型的不同layer 的权重数据放在不同的卡上。
因此需要在构造函数中将模型 split 到不同的 GPU 上。
如上述代码将第一个线性层的权重放在 0 卡,第二个线性层的权重放在 1 卡。 这个进程执行时,CPU 沿着 forward 函数代码开始执行(调度),CPU 在 GPU_0 上 launch 一个 liner 和 一个 relu kernel, 计算的结果存在 GPU_0 上,然后将这个结果拷贝到 GPU_1上, 继续在 GPU_1 上 launch 一个 linear kernnel。最后完成了整个计算。
这种计算方式最大的问题就是在同一时刻,只有一张卡在工作,其他卡在摸鱼。为了避免其他卡摸鱼,文档中用了 Pipeline Inputs
简单来说,当 0 卡把计算结果给到1卡,1卡开始计算时,0卡不能闲着,这时候给 0 卡新的输入数据(之前说 1 卡计算完了之后,再给 0 卡新的输入数据),0卡开始做运算。
文档使用了 resnet50 做了实验,核心代码如下:
class PipelineParallelResNet50(ModelParallelResNet50):
def __init__(self, split_size=20, *args, **kwargs):
super(PipelineParallelResNet50, self).__init__(*args, **kwargs)
self.split_size = split_size
def forward(self, x):
splits = iter(x.split(self.split_size, dim=0))
s_next = next(splits)
s_prev = self.seq1(s_next).to('cuda:1')
ret = []
for s_next in splits:
# A. ``s_prev`` runs on ``cuda:1``
s_prev = self.seq2(s_prev)
ret.append(self.fc(s_prev.view(s_prev.size(0), -1)))
# B. ``s_next`` runs on ``cuda:0``, which can run concurrently with A
s_prev = self.seq1(s_next).to('cuda:1')
s_prev = self.seq2(s_prev)
ret.append(self.fc(s_prev.view(s_prev.size(0), -1)))
return torch.cat(ret)这个代码比较简单,获得了 49% 的加速比。
这和 100% 的加速比还有差距,模型中加了一个参数 split_size。这个参数如果太小,则 forward 中 for 循环的次数增加,这会使得 kernel lauch 的数量较大,影响性能。 如果split_size 很大,则在第一个 split 时和最后一个 split,只有一张卡在工作。因此需要实验才能找到最佳的 split_size。
Intuitively speaking, using small split_size leads to many tiny CUDA kernel launch, while using large split_size results to relatively long idle times during the first and last splits. Neither are optimal.
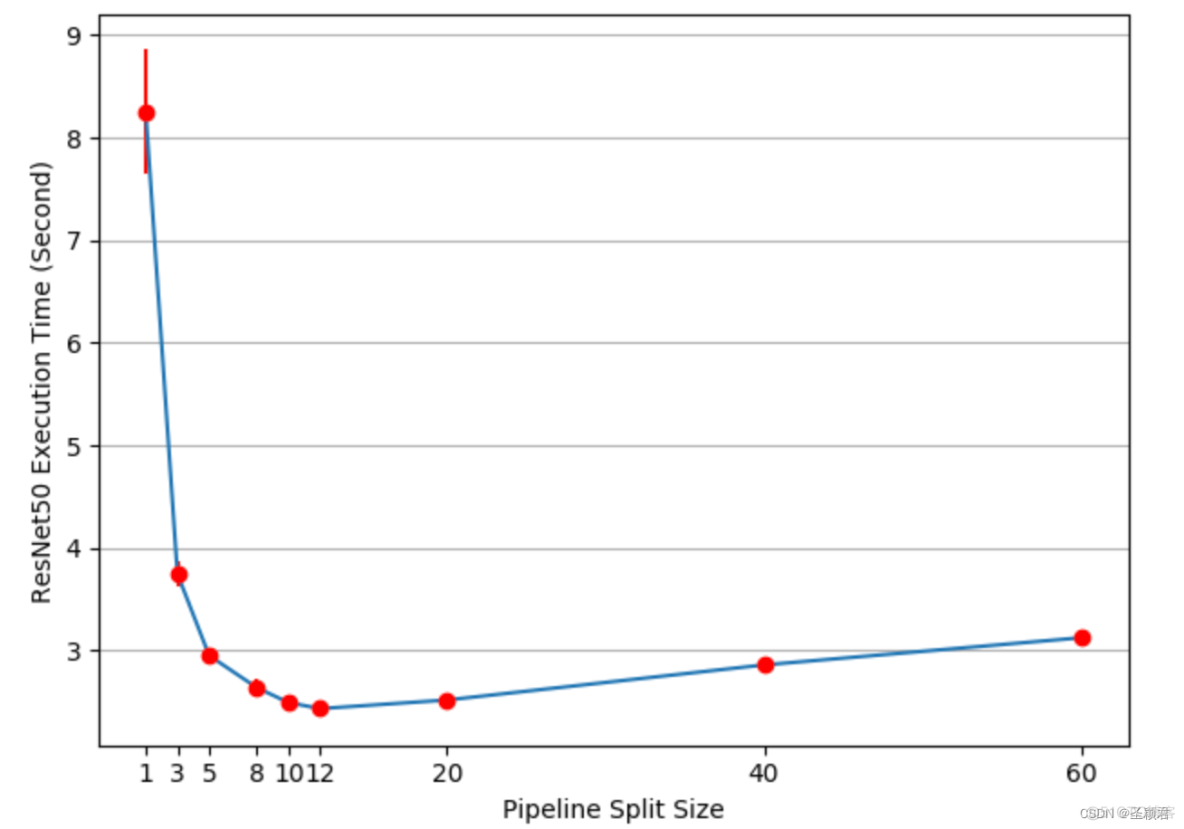
文档中通过实验,发现 split_size = 12 时,可以获得最佳性能。但是加速比依旧只有 3.75/2.43-1=54%。因此还有进一步优化的空间。
优化思路为:
当前 kernel 的计算和数据的拷贝都在同一流上,那么发生数据拷贝时,这张卡就停止计算了。所以一个很容易想到的优化思路是将一张卡上 kernel 计算和数据拷贝放在两个不同的流上, 这样将当前 pre_split 结果的拷贝和 next_split 的计算时间重叠起来。 但这也需要一些同步操作,
比如第二卡上的计算流上的一些 kernel ,需要等待第一张卡上某些 copy 操作完成。
For example, all operations on cuda:0 is placed on its default stream. It means that computations on the next split cannot overlap with the copy operation of the prev split. However, as prev and next splits are different tensors, there is no problem to overlap one’s computation with the other one’s copy.
3. 混合并行(数据并行 + 模型并行/PipeLine并行)
官方文档:GETTING STARTED WITH DISTRIBUTED DATA PARALLEL/Combining DDP with Model Parallelism 最开始看到这个“混合并行时”不免产生了一些疑惑。因为之前的经验告诉我:数据并行要求每张 GPU 卡保存着完整的模型副本(其实这句话是不对的),而模型并行每张卡上只保存着模型的一部分,这听起来是矛盾的。
我们把文档中混合并行部分的完整代码扣出来:
import os
import sys
import tempfile
import torch
import torch.distributed as dist
import torch.nn as nn
import torch.optim as optim
import torch.multiprocessing as mp
from torch.nn.parallel import DistributedDataParallel as DDP
def setup(rank, world_size):
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '12355'
# initialize the process group
dist.init_process_group("gloo", rank=rank, world_size=world_size)
def cleanup():
dist.destroy_process_group()
class ToyMpModel(nn.Module):
def __init__(self, dev0, dev1):
super(ToyMpModel, self).__init__()
self.dev0 = dev0
self.dev1 = dev1
self.net1 = torch.nn.Linear(10, 10).to(dev0)
self.relu = torch.nn.ReLU()
self.net2 = torch.nn.Linear(10, 5).to(dev1)
def forward(self, x):
x = x.to(self.dev0)
x = self.relu(self.net1(x))
x = x.to(self.dev1)
return self.net2(x)
def demo_model_parallel(rank, world_size):
print(f"Running DDP with model parallel example on rank {rank}.")
setup(rank, world_size)
# setup mp_model and devices for this process
dev0 = rank * 2
dev1 = rank * 2 + 1
mp_model = ToyMpModel(dev0, dev1)
ddp_mp_model = DDP(mp_model)
loss_fn = nn.MSELoss()
optimizer = optim.SGD(ddp_mp_model.parameters(), lr=0.001)
optimizer.zero_grad()
# outputs will be on dev1
outputs = ddp_mp_model(torch.randn(20, 10))
labels = torch.randn(20, 5).to(dev1)
loss_fn(outputs, labels).backward()
optimizer.step()
cleanup()
def run_demo(demo_fn, world_size):
mp.spawn(demo_fn,
args=(world_size,),
nprocs=world_size,
join=True)
if __name__ == "__main__":
n_gpus = 4
world_size = n_gpus//2
run_demo(demo_model_parallel, world_size)上面代码需要注意的一点是:device_ids and output_device must NOT be set
因为如果设置的话,这会在进程组内部进程之间广播模型。这并不是模型并行所期望的。
上述代码的分布式示意图如下:
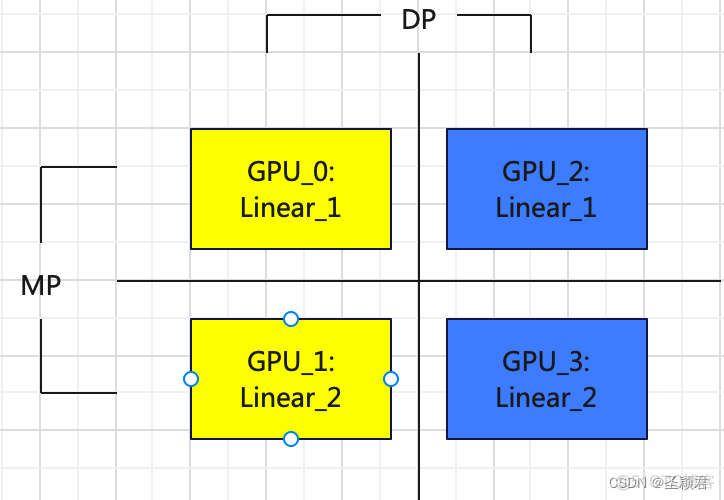
从纵向看,是DP,横向看,是MP。所以只需要两个进程,一个进程管理 GPU_0 和 GPU_1,另外一个进程管理 GPU_2 和 GPU_3 ,这两个进程在同一个进程组中。
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
