
全文链接:http://tecdat.cn/?p=32150
原文出处:拓端数据部落公众号
随着大数据时代的来临,如何从海量的存储数据中发现有价值的信息或知识帮助用户更好决策是一项非常艰巨的任务。数据挖掘正是为了满足此种需求而迅速发展起来的,它是从大量的、不完全的、有噪声的、模糊的、随机的数据中,提取隐含在其中的、人们事先不知道的、但又是潜在的有用信息和知识的过程。由于大数据技术的发展,零售企业可以利用互联网收集大量的销售数据,这些数据是一条条的购买事务信息,每条信息存储了销售事务的处理时间,顾客所购买的商品、各种商品的数量以及价格等。如果对这些历史数据进行分析,则可以对理解分析顾客的购买行为提供有价值的信息。
数据建模
数据来源
本次分析的数据来自电商网站交易数据文件。
指标选取
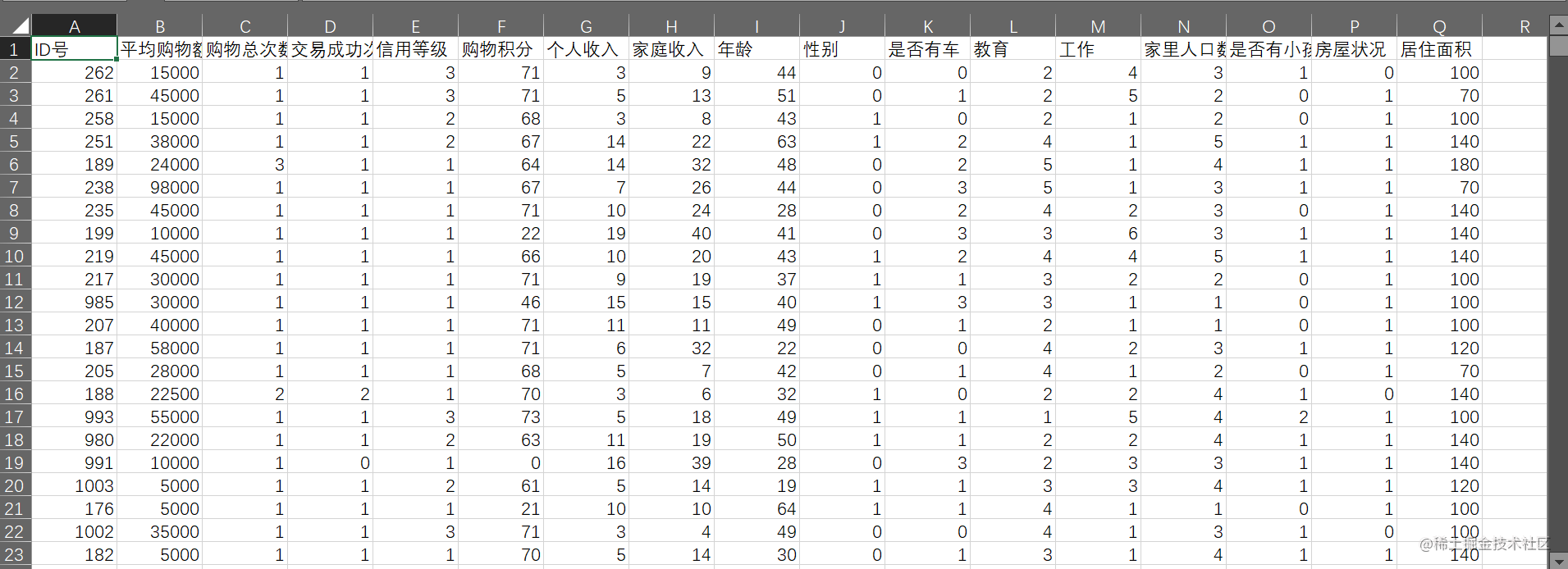
本次分析一共选取了17个指标600个样本,分别是:ID号、平均购物额度、购物总次数、交易成功次数、信用等级、购物积分。
指标介绍
(1)ID号:购网网站上的网购客户ID ;
(2)平均购物额度:网购客户平均的网购服务的金额;
(3)购物总次数:网购客户的每个月购物次数;
(4)交易成功次数:网购客户的交易成功次数;
(5)信用等级:网购客户的购物信用等级;
(6)购物积分:网购客户购物的积分;
(7)Pincome:个人年收入(万元)
(8)Hincome:家庭年收入(万元)
(9)Age:年龄
(10)Gender:性别(0:女;1:男)
(11)Car:家庭拥有汽车的数量
(12)Education:教育水平(1:初中及以下;2:高中;3:专科;4:本科;5:研究生)
(13)Job:工作类型(1:公司职员;2:工厂工人;3:公务员;4:个体;5:事业单位;6:其他)
(14)People:家里人口数量
(15)Children:家里未成年人数量
(16)Housing:房屋拥有类型(0:租房;1:买房)
(17)Area:房屋居住面积(平方米)
数据审核
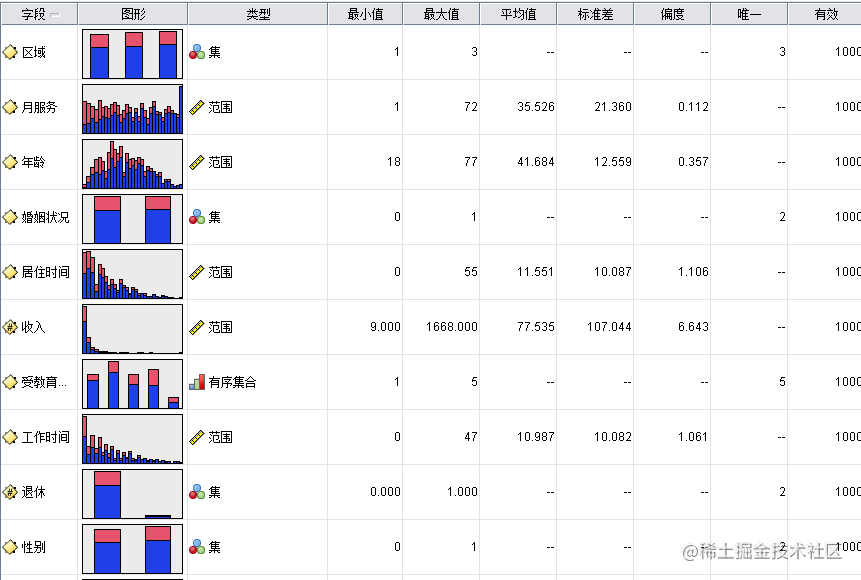
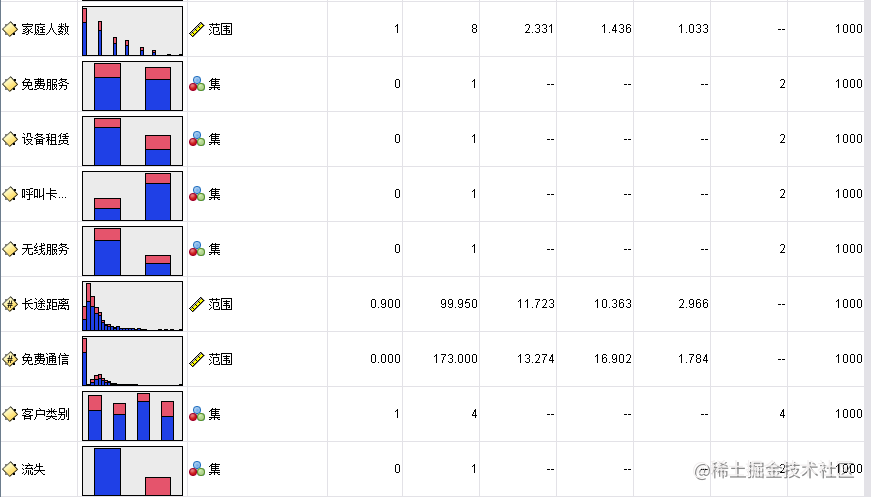
由上表,可得:本次分析的数据都是有效的,不存在缺失值。
描述性统计量
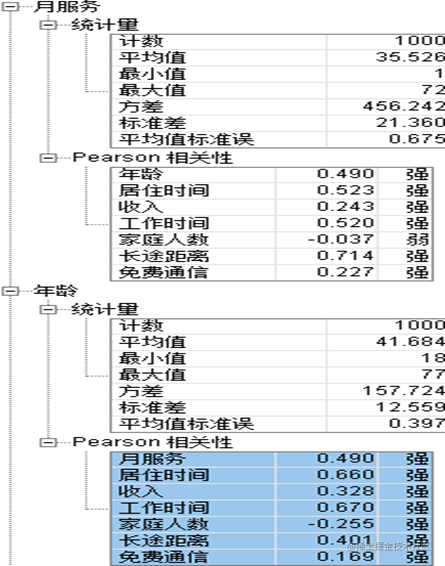
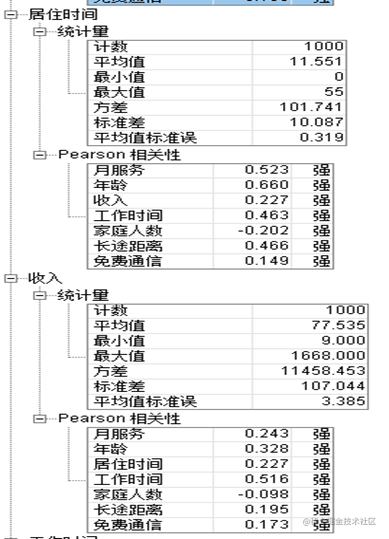
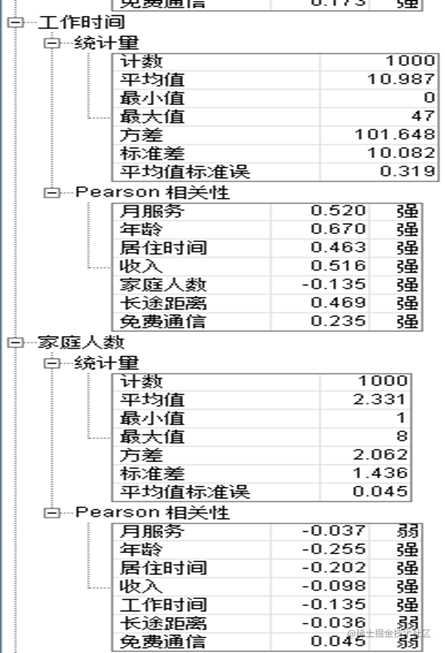
由上表,可得:月服务、年龄、居住时间、收入、工作时间、家庭人数、长途距离、免费通信这8个变量的均值分别为:35.526、41.684、11.551、77.535、10.987、2.331、11.723、13.274,可以看出这8个连续性变量不存在量纲上的差异,因此在后面的分析中,不需要进行标准化处理。同时,这8个变量之间存在较强的线性相关性,说明变量之间存在严重的多重共线性,可以考虑对变量进行降维后在进行分析。
数据归一化
在进行分类之前,为消除量纲的差别,首先对属性进行归一化处理。
Weka数据挖掘流程
数据挖掘一般是指从数据库的大量数据中揭示出隐含的、先前未知的并有潜在价值的信息的非平凡过程,是一种决策支持过程。它实现的过程大致可分为:问题定义、数据收集和预处理、数据挖掘、算法执行,以及结果的分析和评估。
(1)问题定义
数据挖掘的目的是从海里数据中挖掘有效信息,帮助用户更好决策。因此,在数据挖掘之前需定义明确的挖掘目标,明确数据挖掘目的。
(2)数据收集和数据预处理
数据准备又可分为三个子步骤:数据收集、数据预处理和数据变换。数据收集是指收集所有与挖掘业务对象相关的外部和内部数据,从获取的原始数据中,选择出需要挖掘的信息数据,建立挖掘原始数据库。在建立的挖掘原始数据库中,其数据可能是不完全的、有噪声的、随机的、复杂的,数据预处理数据就要对数据进行过滤,清洗掉不完全的、有噪声的数据,为下一步的分析工作做准备。数据转换是指格式化数据,并将其加载到适合分析的存储环境中,形成最终的挖掘数据库。
(3)数据挖掘
算法执行阶段主要根据对问题的定义明确挖掘的任务或目的,数据挖掘是指选择合适的挖掘算法,对转换过的数据库进行有效挖掘,此阶段选好挖掘算法是关键。
(4)结果分析和评估
数据挖掘阶段发现的模式,经过评估,可能存在冗余或无关的模式,这时需要剔除;模式也有可能不满足用户要求,这时则需要整个发现过程回退到前一个阶段,如重新选取数据、采用新的数据变换方法、设定新的参数值,甚至换一种算法等。
模型的实际应用
研究数据说明
本文数据来源于平台后台数据库中历史交易信息,包括网购相关信息以及网购用户信息等。
经过数据筛选梳理,最终研究的样本包括999条网购列表。其中,248审核未通过的有条;209条是网购放弃;542条成功网购,169条已还完网购。成功交易总额达3090.93万元。
网购用户关联规则算法分析设计
本文分别用Apriori算法对数据进行处理挖掘,具体结果如下所示。
(1)Apriori算法
虽然 Apriori 算法可以直接挖掘生成表中的交易数据集,但是为了关联挖掘其他算法的需要先把交易数据集转换成分析数据集,构建的数据流程图如图 1 所示。
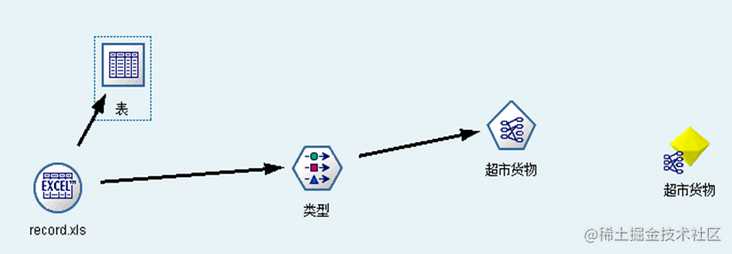
图 1 商品关联规则 Apriori 算法挖掘流图
关联规则模型Apriori模型参数设置
通过格式转换, 设最低条件支持度为15%,最小规则置信度为30%,最大前项数为5,选择专家模式,挖掘出最有价值的10条关联规则,如图所示。生成的10条规则如下所示:
1. 交易成功次数=1 469 ==> 购物总次数=1 465 lift:(1.06) lev:(0.05) [27] conv:(6.25)
2. 交易成功次数=1 房屋状况=1 423 ==> 购物总次数=1 419 lift:(1.06) lev:(0.04) [24] conv:(5.64)
3. 是否有小孩=1 房屋状况=1 365 ==> 购物总次数=1 345 lift:(1.01) lev:(0.01) [4] conv:(1.16)
4. 是否有小孩=1 397 ==> 购物总次数=1 375 lift:(1.01) lev:(0.01) [4] conv:(1.15)
5. 房屋状况=1 545 ==> 购物总次数=1 508 lift:(1) lev:(0) [0] conv:(0.96)
6. 购物总次数=1 是否有小孩=1 375 ==> 房屋状况=1 345 lift:(1.01) lev:(0.01) [4] conv:(1.11)
7. 是否有小孩=1 397 ==> 房屋状况=1 365 lift:(1.01) lev:(0.01) [4] conv:(1.1)
8. 购物总次数=1 560 ==> 房屋状况=1 508 lift:(1) lev:(0) [0] conv:(0.97)
9. 交易成功次数=1 469 ==> 房屋状况=1 423 lift:(0.99) lev:(-0.01) [-3] conv:(0.91)
10. 购物总次数=1 交易成功次数=1 465 ==> 房屋状况=1 419 lift:(0.99) lev:(-0.01) [-3] conv:(0.91) 分析及建议: 通过结果可以清晰的看到交易次数较多的顾客购物成功次数比较多,另外是否有小孩、是否有房屋对顾客是否购物成功次数也有关联,建议网站可以加大对这些用户的推荐购买力度,由上述结果可知,同时购物且成功的用户占总用户的的90%,有房屋的用户成功购物分别占总订单数的91%,有小孩的人有91%会网购, 房屋面积越大,网购次数越高,由此可见,房屋、网购、是否有小孩、网购成功次数这几个变量关联度较高,可以对这些用户进行广告策略投放,从而增加用户网购的成功率。
Associator Model
Apriori
=======
Minimum support: 0.55 (330 instances)
Minimum metric : 0.9
Number of cycles performed: 9
Generated sets of large itemsets:
Size of set of large itemsets L(1): 4
Size of set of large itemsets L(2): 5
Size of set of large itemsets L(3): 2
结论与展望
结论
数据挖掘中的关联规则侧重于不同对象之间的联系,本文讨论了关联规则挖掘在用户网购策略中的应用。利用WEKA软件,通过实例分析了频繁项集及关联规则生成的过程,采用Apriori算法对数据分别进行了解析挖掘,针对挖掘结果提出了相应的建议,对电商网站的发展有着到重要的现实的意义。

最受欢迎的见解
1.[](http://tecdat.cn/r%e8%af%ad%e8%a8%80%e7%bb%98%e5%88%b6%e7%94%…)Python中的Apriori关联算法-市场购物篮分析
2.[](http://tecdat.cn/r%e8%af%ad%e8%a8%80%e7%94%9f%e5%ad%98%e5%88%…)[](http://tecdat.cn/%e9%80%9a%e8%bf%87%e5%85%b3%e8%81%94%e8%a7%8…)R语言绘制生存曲线估计|生存分析|如何R作生存曲线图
3.[](http://tecdat.cn/r%e8%af%ad%e8%a8%80%e5%a6%82%e4%bd%95%e5%9c%…)[](http://tecdat.cn/%e5%9f%ba%e4%ba%8er%e7%9a%84fp%e6%a0%91fp-gr…)用关联规则数据挖掘探索药物配伍中的规律
4.[](http://tecdat.cn/r%e8%af%ad%e8%a8%80%e4%b8%ad%e4%bd%bf%e7%94%…)通过Python中的Apriori算法进行关联规则挖掘
5.[](http://tecdat.cn/r%e8%af%ad%e8%a8%80%e7%94%9f%e5%ad%98%e5%88%…)用关联规则数据挖掘探索药物配伍中的规律
6.[](http://tecdat.cn/r%e8%af%ad%e8%a8%80ggplot2%e8%af%af%e5%b7%ae…)采用SPSS Modeler的Web复杂网络对所有腧穴进行分析
7.[](http://tecdat.cn/r-%e8%af%ad%e8%a8%80%e7%bb%98%e5%88%b6%e5%8a…)R语言如何在生存分析与COX回归中计算IDI,NRI指标
8.R语言如何找到患者数据中具有差异的指标?(PLS—DA分析)
9.R语言中的生存分析Survival analysis晚期肺癌患者4例
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
