
1、简介
SIMD(Single Instruction, Multiple Data)是一种并行计算技术,它通过向量寄存器存储多个数据元素,并使用单条指令同时对这些数据元素进行处理,从而提高了计算效率。SIMD已被广泛应用于需要大量数据并行计算的领域,包括图像处理、视频编码、信号处理、科学计算等。许多现代处理器都提供了SIMD指令集扩展,例如x86平台的SSE/AVX,以及ARM平台的NEON,本文只讨论x86平台下的SIMD指令。
在C++程序中使用SIMD指令有两种方案,一种是使用内联汇编,另一种是使用intrinsic函数。以简单的数组相乘为例,代码的常规写法、内联汇编写法以及intrinsic函数写法分别如下:
float a[4] = { 1.0, 2.0, 3.0, 4.0 };
float b[4] = { 5.0, 6.0, 7.0, 8.0 };
float c[4];
// 常规写法,用循环实现数组相乘
for (int i = 0; 服务器托管网i intrinsic函数是对汇编指令的封装,编译时这些函数会被内联成汇编,所以不会产生函数调用的开销。当CPU不支持指令集时,intrinsic函数可能会模拟对应的功能。完整的intrinsic函数使用指南可以参考Intel官方文档。
2、指令集的发展
2.1、MMX
1996年,Intel推出了多媒体扩展指令集MMX(Multi-Media Extensions),它最初是为了加速多媒体应用程序而设计的,共包含57条指令,可用于整数的加法、减法、乘法、逻辑运算和移位等。MMX引入了8个64位寄存器,被称为MM0~MM7,每个寄存器可以被看做是2个32位整数、或是4个16位整数、或是8个8位整数。不过,这些MMX寄存器并不是独立的寄存器,而是复用了浮点数寄存器,所以MMX指令和浮点数操作不能同时工作。
2.2、SSE
SSE(Streaming SIMD Extensions)指令集发布于1999年,作为对MMX指令集的增强和扩展。SSE支持单精度浮点数运算以及整数运算等指令,并引入了8个独立的128位寄存器,称为XMM0~XMM7。后续发布的SSE2指令集则一方面添加了对双精度浮点数的支持,另一方面也增添了整数处理指令,这些新的整数处理指令能够覆盖MMX指令的功能,从而让旧的MMX指令显得多余。2003年,AMD推出AMD64架构时,又新增了8个XMM寄存器,它们被称为XMM8~XMM15。当CPU处于32位模式时,可用的XMM寄存器为XMM0~XMM7,而当CPU处于64位模式时,可用的XMM寄存器为XMM0~XMM15。此后推出的SSE3/SSE4又添加了更多了SIMD指令。
2.3、AVX
2011年,AVX(Advanced Vector Extensions)指令集将浮点运算宽度从128位扩展到了256位,新的寄存器名为YMM0~YMM15,其128位的下半部分仍可作为XMM0~XMM15访问。2013年,AVX2将整数运算指令扩展至256位,同时也支持了FMA(Fused Multiply Accumulate)指令。2016年,AVX-512将浮点与整数运算宽度扩展到了512位,主要用于多媒体信息处理、科学计算、数据加密和压缩、以及深度学习等高性能计算场景。
2.4、对比总结
每一代的指令集都兼容上一代,也就是说新一代的指令集也支持使用上一代的指令和寄存器(但硬件实现可能有区别)。此外,AVX对之前的部分指令进行了重构,所以不同代际之间相同功能的函数可能具有不同的接口。不同代际的指令尽量不要混用,因为每次状态切换会有性能消耗,从而拖慢程序的运行速度。代际之间对寄存器及其位宽的更新情况如下:
| 指令集 | 寄存器 | 浮点位宽 | 整型位宽 |
|---|---|---|---|
| MMX | MM0~MM7 | 64 | |
| SSE | XMM0~XMM7 | 128 | |
| SSE2 | XMM0~XMM15 | 128 | 128 |
| AVX | YMM0~YMM15 | 256 | 128 |
| AVX2 | YMM0~YMM15 | 256 | 256 |
3、SIMD编程基础
3.1、头文件
#include // MMX
#include // SSE(include mmintrin.h)
#include // SSE2(include xmmintrin.h)
#include // SSE3(include emmintrin.h)
#include // SSSE3(include pmmintrin.h)
#include // SSE4.1(include tmmintrin.h)
#include // SSE4.2(include smmintrin.h)
#include // SSE4A
#include // AES(include nmmintrin.h)
#include // AVX, AVX2, FMA(include wmmintrin.h)
- 每一代SIMD指令集的头文件如上,实际使用时只需包含最高支持的指令集头文件即可。
- SSE4A是AMD独有的指令集,除
之外的每一个头文件都包含了它前面的那个头文件。 - 部分编译器还有
用于支持AVX-512。 - 如果想要包含全部头文件,在GCC/Clang环境下可以包含头文件
,在MSVC环境下则需要包含。
3.2、内存对齐
有很多SIMD指令都要求内存对齐。例如SSE指令_mm_load_ps就要求输入地址是16字节对齐的,否则可能导致程序崩溃或者得不到正确结果;如果程序无法保证输入地址是对齐的,那就得使用不要求内存对齐的版本_mm_loadu_ps。内存不对齐的版本通常运行更慢,不过在较新的CPU上这种性能差距已经基本可以忽略了。
在栈上内存定义变量时,可以使用如下两种方法进行16字节的内存对齐:
_MM_ALIGN16 float a[4] = { 1.0, 2.0, 3.0, 4.0 }; //_MM_ALIGN16是头文件xmmintrin.h中定义的宏
alignas(16) float b[4] = { 5.0, 6.0, 7.0, 8.0 }; //alignas是C++11中引入的关键字
对于堆上分配的动态内存,可用下列函数进行16字节对齐内存的分配与释放:
float* a = (float*)_aligned_malloc(4 * sizeof(float), 16);
_aligned_free(a);
3.3、数据类型
SIMD指令使用自定义的数据类型,例如__m64、__m128、__m128d、__m128i等。它们的命名通常由3部分组成:
- 前序:统一为
__m - 位宽:例如
64、128、256、512 - 类型:
i表示整型(int),d表示双精度浮点型(double),什么都不加表示单精度浮点型(float)
以AVX中的256位数据类型为例,它们的定义如下:
typedef union __declspec(intrin_type) __declspec(align(32)) __m256 {
float m256_f32[8];
} __m256;
typedef struct __declspec(intrin_type) __declspec(align(32)) __m256d {
double m256d_f64[4];
} __m256d;
typedef union __declspec(intrin_type) __declspec(align(32)) __m256i {
__int8 m256i_i8[32];
__int16 m256i_i16[16];
__int32 m256i_i32[8];
__int64 m256i_i64[4];
unsigned __int8 m256i_u8[32];
unsigned __int16 m256i_u16[16];
unsigned __int32 m256i_u32[8];
unsigned __int64 m256i_u64[4];
} __m256i;
SIMD寄存器将自己暴露为上面这样的数据类型供C++程序员使用,在汇编代码中,相同位宽的数据类型对应着同样的寄存器,它们的区别仅在于C++的类型检查。
编译器会自动为寄存器分配变量,但寄存器的数量是有限的。如果定义了太多局部变量,并且代码依赖关系复杂导致编译器无法重复使用寄存器,那么部分变量可能会从寄存器中转移到内存上,某些情况下这会使得性能下降。
对于这些向量类型,虽然编译器将它们定义为内部包含数组的结构体或联合体,程序员可以使用这些数组来访问向量的各个通道,但这样的性能可能并不理想,因为编译器在执行此类代码时可能会将数据在寄存器和内存之间来回转移。所以建议不要这样处理SIMD向量数据,而应当尽量使用洗牌、插入、提取等intrinsic函数来完成此类操作。
3.4、运算模式
浮点数运算模式可以分为packed和scalar两类。packed模式一次对寄存器中的四个浮点数进行计算,而scalar模式一次只对寄存器中最低的一个浮点数进行计算。
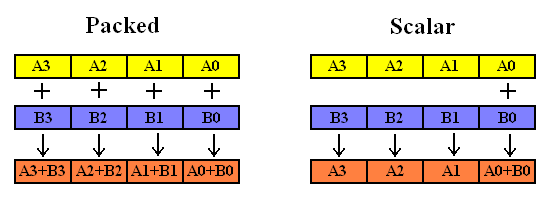
3.5、函数命名
SIMD指令的intrinsic函数命名风格如下:
_mm__
第一部分mm表示数据向量的位宽,例如_mm代表64或128位,_服务器托管网mm256代表256位,_mm512代表512位。
第二部分表示函数的功能,例如load、add、store等。此外也可以追加一个修饰字符来实现某种特殊作用,例如:
| 修饰字符 | 示例 | 作用 |
|---|---|---|
| u | loadu | [unaligned] 允许内存未对齐 |
| s | adds/subs | [saturate] 当运算结果超出数据范围时,会被限制为该范围的上限或者下限 |
| h | hadd/hsub | [horizontal] 水平方向上做加减法 |
| hi/lo | mulhi/mullo | [high/low] 相乘后保留高位/低位 |
| r | setr | [reverse] 逆序初始化向量 |
| fm | fmadd/fmsub | [fused multiply add] FMA运算 |
第三部分表示数据类型,如下表所示:
| 数据标识 | 含义 |
|---|---|
| epi8/epi16/epi32 | 有符号的8/16/32位整数向量 |
| epu8/epu16/epu32 | 无符号的8/16/32位整数向量 |
| si128/si256 | 未指定的128位/256位向量 |
| ps | packed single |
| ss | scalar single |
| pd | packed double |
| sd | scalar double |
3.6、指令集支持
MSVC没有提供检测指令集支持性的方法。而对于GCC来说,可以使用编译选项来启用各种指令集,也可以在代码中使用宏来判断是否支持对应的指令集:
| GCC编译选项 | 宏 |
|---|---|
-mmmx |
__MMX__ |
-msse |
__SSE__ |
-msse2 |
__SSE2__ |
-msse3 |
__SSE3__ |
-mssse3 |
__SSSE3__ |
-msse4.1 |
__SSE4_1__ |
-msse4.2 |
__SSE4_2__ |
-mavx |
__AVX__ |
-mavx2 |
__AVX2__ |
若要检测CPU是否支持特定的SIMD指令集,可以参考这个开源项目,它包含了多种系统环境下检测指令集的代码。下面这段代码改编自上述开源项目,可以在MSVC x86环境下检测CPU对SIMD指令集的支持情况:
#include
int main()
{
int info[4];
__cpuid(info, 0);
unsigned int maximum_eax = info[0];
if (maximum_eax >= 1)
{
__cpuid(info, 1);
unsigned int ecx = info[2];
unsigned int edx = info[3];
bool has_mmx = edx & (1 = 7)
{
__cpuidex(info, 7, 0);
unsigned int ebx = info[1];
unsigned int ecx = info[2];
unsigned int edx = info[3];
bool has_avx2 = ebx & (1 3.7、混用AVX/SSE
AVX采用了更宽的256位向量和新指令,并使用了新的VEX编码格式。 不过AVX也包含128位的VEX编码指令,它们相当于传统SSE的128位指令。
| 指令 | 编码方式 | 使用的寄存器 |
|---|---|---|
| 256位AVX指令 | VEX | 256位YMM寄存器 |
| 128位AVX指令 | VEX | 对YMM低128位进行操作,并将高128位清零 |
| 128位传统SSE指令 | legacy | 对XMM(即YMM的低128位)进行操作,并且不关心YMM的高128位 |
AVX指令与传统(非VEX编码)SSE指令混合使用时可能会导致性能下降,因为当从AVX指令转换到传统SSE指令时,硬件会保存YMM寄存器高128位的内容,然后在SSE转换回AVX时恢复这些值,保存和恢复操作都会花费几十个时钟周期。
避免这种性能损失最简单的方法就是使用编译器标志-mavx(对于Windows则是/arch:avx),这会强制编译器为128位指令进行VEX格式编码。如果确实无法避免AVX与传统SSE的转换(例如需要调用使用了传统SSE指令的库),可以使用_mm256_zeroupper将YMM寄存器的高128位清零,这样硬件就无需保存这些值,另外需要注意的是,_mm256_zeroupper指令必须在256位AVX指令之后、SSE指令之前调用,这样才可以取消保存和还原操作,其它方法(例如XOR)不起作用。关于AVX-SSE混用问题的详细应对策略可以参考Intel官方文档Avoiding AVX-SSE Transition Penalties。
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
OSC 请你来轰趴啦!1028 苏州源创会,一起寻宝 AI 时代 作者 | Xiaodong 导读 本文主要介绍了智能问答技术在百度搜索中的应用。包括机器问答的发展历程、生成式问答、百度搜索智能问答应用。欢迎大家加入百度搜索团队,共同探索智能问答技术的发展方向…
