

作者 | Fengwen、BBuf
欢迎Star、试用One-YOLOv5:
https://github.com/Oneflow-Inc/one-yolov5
1
结构项目预览
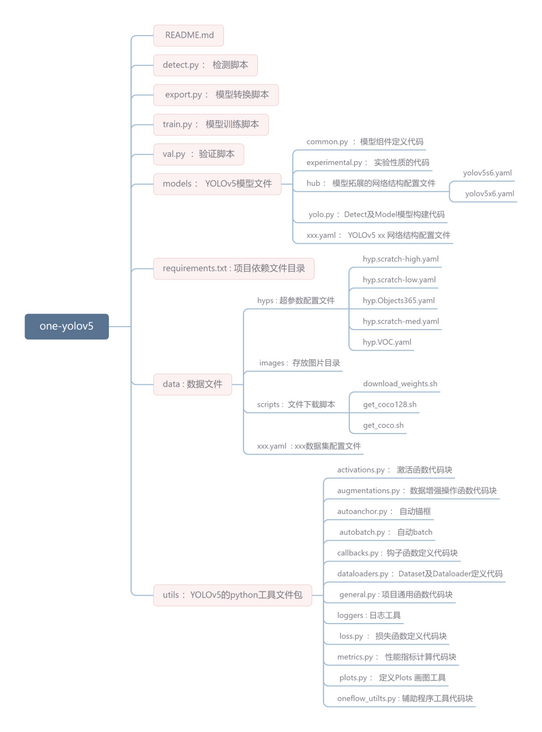
2
安装
git clone https://github.com/Oneflow-Inc/one-yolov5 # clone
cd one-yolov5
pip install -r requirements.txt # install3
训练
两种训练方式
1.带权重训练
$ python path/to/train.py --data coco.yaml --weights yolov5s --img 640- 不带权重训练
$ python path/to/train.py --data coco.yaml --weights '' --cfg yolov5s.yaml --img 640单GPU训练
$ python train.py --data coco.yaml --weights yolov5s --device 0多GPU训练
$ python -m oneflow.distributed.launch --nproc_per_node 2 train.py --batch 64 --data coco.yaml --weights yolov5s --device 0,1注意:
- –nproc_per_node 指定要使用多少GPU。举个例子:在上面多GPU训练指令中它是2。
- –batch 是总批量大小。它将平均分配给每个GPU。在上面的示例中,每GPU是64/2=32。
- –cfg : 指定一个包含所有评估参数的配置文件。
- 上面的代码默认使用GPU 0…(N-1)。使用特定的GPU?可以通过简单在 –device 后跟指定GPU来实现。「案例」,在下面的代码中,我们将使用GPU 2,3。
$ python -m oneflow.distributed.launch --nproc_per_node 2 train.py --batch 64 --data coco.yaml --cfg yolov5s.yaml --weights '' --device 2,3恢复训练
如果你的训练进程中断了,你可以这样恢复先前的训练进程。
# 多卡训练.
python -m oneflow.distributed.launch --nproc_per_node 2 train.py --resume你也可以通过 –resume 参数指定要恢复的模型路径。
# 记得把 /path/to/your/checkpoint/path 替换为你要恢复训练的模型权重路径
--resume /path/to/your/checkpoint/path使用SyncBatchNorm
SyncBatchNorm可以提高多gpu训练的准确性,但会显著降低训练速度。它仅适用于多GPU DistributedDataParallel 训练。建议最好在每个GPU上的样本数量较小(样本数量
要使用SyncBatchNorm,只需将添加 –sync-bn 参数选项,具体「案例」如下:
$ python -m oneflow.distributed.launch --nproc_per_node 2 train.py --batch 64 --data coco.yaml --cfg yolov5s.yaml --weights '' --sync-bn4
评估
下面的命令是在COCO val2017数据集上以640像素的图像大小测试 yolov5x 模型。yolov5x是可用小模型中最大且最精确的,其它可用选项是 yolov5n ,yolov5m,yolov5s,yolov5l ,以及他们的 P6 对应项比如 yolov5s6 ,或者你自定义的模型,即 runs/exp/weights/best 。
$ python val.py --weights yolov5x --data coco.yaml --img 640 5
推理
首先,下载一个训练好的模型权重文件,或选择你自己训练的模型;然后,通过 detect.py文件进行推理。
python path/to/detect.py --weights yolov5s --source 0 # webcam
img.jpg # image
vid.mp4 # video
path/ # directory
path/*.jpg # glob
'https://youtu.be/Zgi9g1ksQHc' # YouTube
'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream6
训练结果
本地日志
默认情况下,所有结果都记录为runs/train,并为每个新训练创建一个新的训练结果目录,如runs/train/exp2、runs/train/exp3等。查看训练和测试JPG以查看 mosaics, labels, predictions and augmentation 效果。注意:Mosaic Dataloader 用于训练(如下所示),这是Ultralytics发表的新概念,首次出现在YOLOv4中。
train_batch0.jpg 显示 batch 为 0 的 (mosaics and labels):

val_batch0_labels.jpg 展示测试 batch 为 0 的labels:

val_batch0_pred.jpg 展示测试 batch 为 0 predictions(预测):

训练训损失和性能的指标有记录到Tensorboard和自定义结果中results.csv日志文件,训练训完成后作为结果绘制 results.png如下。在这里,我们展示了在COCO128上训练的YOLOV5结果
- 从零开始训练 (蓝色)。
- 加载预训练权重 –weights yolov5s (橙色)。
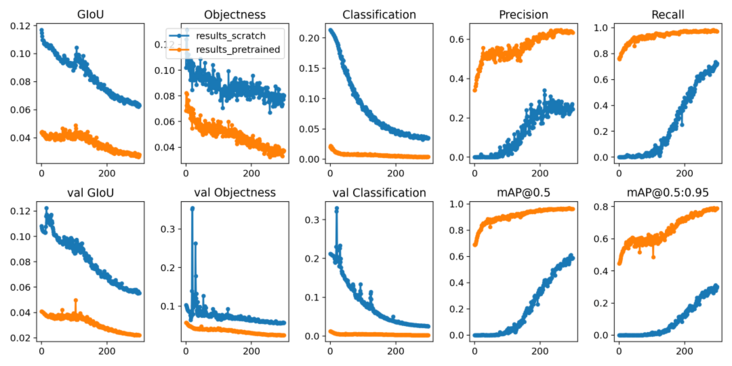
具体的指标分析详见文章《模型精确度评估》(https://mp.weixin.qq.com/s/nvfAU6TwTDoZhF8zFpCaOw)
7
训练技巧
声明:大多数情况下,只要数据集足够大且标记良好,就可以在不改变模型或训练设置的情况下获得良好的结果。如果一开始你没有得到好的结果,你可以采取一些步骤来改进,但我们始终建议用户在考虑任何更改之前先使用所有默认设置进行一次训练。这有助于建立评估基准和发现需要改进的地方。
模型选择
类似于YOLOv5x和YOLOv5x6的大型模型在几乎所有情况下都会产生更好的结果,但参数更多,需要更多的CUDA内存进行训练,运行速度较慢。
对于移动部署,我们推荐YOLOv5s/m,对于云部署,我们建议YOLOV5l/x。
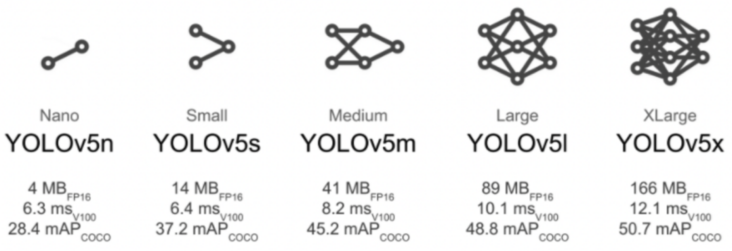
(有关所有模型的完整比较)
- 从预先训练的权重开始训练。建议用于中小型数据集(即VOC、VisDrone、GlobalWheat)。将模型的名称传递给–weights参数。模型自动从latest YOLOv5 releasse 下载 。
python train.py --data custom.yaml --weights yolov5s
yolov5m
yolov5l
yolov5x
custom_pretrained # 自定义的网络结构文件- 从头开始训练的话,推荐用大的数据集(即 COCO、Objects365、OIv6 )在 –cfg 选项后传递你感兴趣的网络结构文件参数 以及空的 –weights ” 参数:
python train.py --data custom.yaml --weights '' --cfg yolov5s.yaml
yolov5m.yaml
yolov5l.yaml
yolov5x.yaml训练配置
在修改任何内容之前,首先使用默认设置进行训练,以建立性能基线。训练参数的完整列表,能够在train.py文件中发现。
- Epochs : 默认训练300个epochs。如果早期过拟合,则可以减少训练。如果在300个周期后未发生过拟合,则可以训练更长,比如600、1200个epochs。
- Image size: COCO以 –img 640,的分辨率进行训练,但由于数据集中有大量的小对象,它可以从更高分辨率(如–img 1280)的训练中训练。如果有许多小对象,则自定义数据集将从更高分辨率的训练中获益。最好的推断结果是在相同的–img 处获得的 ,即如果在-img 1280处进行训练,也应该在–img 1280处进行测试和检测。
- Batch Size: 使用更大的 –batch-size 。能够有效缓解小样本数产生的batchnorm统计的错误。
- Hyperparameters:默认超参数在hyp.scratch-low.yaml文件中。我们建议你在考虑修改任何超参数之前,先使用默认超参数进行训练。一般来说,增加增强超参数将减少和延迟过度拟合,允许更长的训练和得到更高mAP值。减少损耗分量增益超参数,如hyp[‘obj’],将有助于减少这些特定损耗分量中的过度拟合。有关优化这些超参数的自动化方法,请参阅我们的 《超参数演化教程》。
…更多训练的超参数配置请查看本文的附录。
8
拓展
使用多机训练
这仅适用于多GPU分布式数据并行训练。
在训练之前,确保所有机器上的文件都相同,数据集、代码库等。之后,确保机器可以相互通信。
你必须选择一台主机器(其他机器将与之对话)。记下它的地址(master_addr)并选择一个端口(master-port)。对于下面的示例,将使用master_addr=192.168.1.1和master_ port=1234。
要使用它,可以执行以下指令:
# On master machine 0
$ python -m oneflow.distributed.launch --nproc_per_node G --nnodes N --node_rank 0 --master_addr "192.168.1.1" --master_port 1234 train.py --batch 64 --data coco.yaml --cfg yolov5s.yaml --weights ''# On machine R
$ python -m oneflow.distributed.launch --nproc_per_node G --nnodes N --node_rank R --master_addr "192.168.1.1" --master_port 1234 train.py --batch 64 --data coco.yaml --cfg yolov5s.yaml --weights ''其中G是每台机器的GPU数量,N是机器数量,R是从0到(N-1)的机器数量。
假设我有两台机器,每台机器有两个GPU,对于上面的情况,G=2,N=2,R=1。
在连接所有N台机器之前,训练不会开始。输出将仅显示在主机上!
注意:
- oneflow目前不支持windows平台
- –batch 必须是GPU数量的倍数。
- GPU 0 将比其他GPU占用略多的内存,因为它维护EMA并负责检查点等。
- 如果你得到 RuntimeError: Address already in use ,可能是因为你一次正在运行多个训练程序。要解决这个问题,只需通过添加–master_port来使用不同的端口号,如下所示
$ python -m oneflow.distributed.launch --master_port 1234 --nproc_per_node 2 ...配置代码
# prepare
t=https://github.com/Oneflow-Inc/one-yolov5:latest && sudo docker pull $t && sudo docker run -it --ipc=host --gpus all -v "$(pwd)"/coco:/usr/src/coco $t
pip install --pre oneflow -f https://staging.oneflow.info/branch/master/cu112
cd .. && rm -rf app && git clone https://github.com/Oneflow-Inc/one-yolov5 -b master app && cd app
cp data/coco.yaml data/coco_profile.yaml
# profile
python train.py --batch-size 16 --data coco_profile.yaml --weights yolov5l --epochs 1 --device 0
python -m oneflow.distributed.launch --nproc_per_node 2 train.py --batch-size 32 --data coco_profile.yaml --weights yolov5l --epochs 1 --device 0,1
python -m oneflow.distributed.launch --nproc_per_node 4 train.py --batch-size 64 --data coco_profile.yaml --weights yolov5l --epochs 1 --device 0,1,2,3
python -m oneflow.distributed.launch --nproc_per_node 8 train.py --batch-size 128 --data coco_profile.yaml --weights yolov5l --epochs 1 --device 0,1,2,3,4,5,6,7
附件
train.py参数解析表

Reference
- https://github.com/ultralytics/yolov5/wiki/Train-Custom-Data
- https://docs.ultralytics.com/quick-start/
欢迎 Star、试用 OneFlow 最新版本:https://github.com/Oneflow-Inc/oneflow/
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
