
1 卫星影像金字塔分块原理说明

通常我们在工作中使用的卫星影像数据,轻则几百M,重则几百个G甚至上TB级。影像数据太大,是大家经常会遇到的一个问题,尤其是想下载一个省以上数据的时候该问题尤为突出。那么该问题是否有一个比较好的解决方案呢?
以全球为例,我们以19级为例,共有2^18 * 2^17 张瓦片,如此多的瓦片会让磁盘愈来愈慢,同时也无法维护。
当影像范围比较大时,我们可以采用金字塔分块的方式进行管理,系统会自动将大范围分成若干个块,且块与块之间是可以无缝拼接的。
一般情况我们选择全球前10级别作为基础级别,因数据量不大(1G)左右,后续以10级作为基础级别,全球19级别数据被划分为 2^8 * 2^7(512 * 256)个块。每个块中包含了256 * 256 张小瓦片。
1.1 Fepk文件命名规则
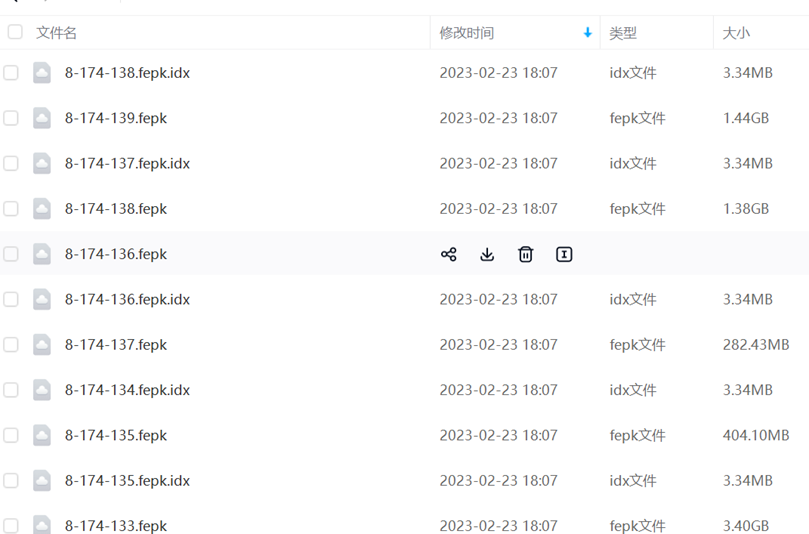
文件说明(包含索引与数据两个文件,文件必须都配套才可以正常使用):
*.fepk :文件中存储具体的瓦片数据。
*.fepk.idx :文件中存储的瓦片的索引信息,当给定一个瓦片编号后,可以根据编号计算出来瓦片存在索引中的信息(大小,以及数据在8-174-138.fepk中的位置)。
名称命名规
以8-174-138.fepk为例:其中8是级别,174是列号,138是行号,文件中存储了8-174-138瓦片裂分出来的所有瓦片数据。
2 .fepk文件格式说明
我们一般不会直接采用瓦片作为管理单元,会把一个块作为管理单元,把数据划分为索引文件与数据文件,如下所示:
数据文件:world.fepk
索引文件:world.fepk.idx
2.1 索引文件
表 1文件说明
|
文件头 |
字段 |
值 |
|
文件头 |
char szMagic[20] |
fe.tile.store.data20字节 |
|
uint version |
版本号4字节 |
|
|
uint typeId |
数据类型 enum PKType { PK_IMAGE , PK_DEM, PK_VEC, PK_QXSY, PK_USER, };4字节 |
|
|
uint wgs84 |
是否是wgs84经纬投影4字节 |
|
|
uint flag |
4字节 |
|
|
uint64 timestamp |
时间戳8字节 |
|
|
real2 vStart |
经纬度最小范围8*2字节 |
|
|
real2 vEnd |
经纬度最大范围 8*2字节 |
|
|
LevSnap levOff[24] |
级别索引,8 * 24 字节 |
|
|
char _reserve[240] |
保留 |
|
|
级别1 |
int2 _start |
2 * 4字节,瓦片最小行列号 |
|
int2 _end |
2 * 4字节,瓦片最大行列号 |
|
|
uint64 _offset |
8字节 |
|
|
uint64 _dataSize |
8字节 |
|
|
uint _lev |
4字节 |
|
|
char _reserve[216] |
216字节 |
|
|
瓦片数据索引矩阵数据PKTLHeader |
N * PKTLHeader N = (_end.x |
|
|
|
PKTLHeader |
|
|
级别2 |
|
|
|
级别3 |
|
|
|
级别… |
|
|
PKTLHeader定义:
PKTLHeader定义: struct 服务器托管网 PKTLHeader { /// 有无数据标记,即服务器上是否有该数据 0,无,1,有 uint64 _data:2; /// 在本文件中是否已经存储 0,无,1,有 uint64 _stored:2; /// 状态, uint64 _state :6; /// 数据地址,使用50个bit最大 2^54 /// 单个文件最大16 K T uint64 _offset : 54; /// 如果该值!= 0xFFFF,则有效,否则无效, /// 使用该字段的意义在于解决网络读取问题,比如在云盘上 /// 先读取索引,如果没有数据大小,或者数据大小存储在数据文件中,则需要 /// 再次访问数据文件,才可以得大小,增加额外的IO,同时兼顾大小,该变量最大可以存储64K /// 如果超过了64K,那么一样的需要访问数据文件获取大小 ushort _dataSize; };
共计10自字节
LevSnap定义:
struct LevSnap { uint64 _lev:8; uint64 _offset:56; };
共计8字节
2.2 数据文件文件
|
文件头 |
字段 |
值 |
|
文件头 |
char szMagic[20] |
fe.tile.store.data20字节 |
|
uint version |
版本号4字节 |
|
|
uint typeId |
数据类型 enum PKType { PK_IMAGE , PK_DEM, PK_VEC, PK_QXSY, PK_USER, };4字节 |
|
|
uint wgs84 |
是否是wgs84经纬投影4字节 |
|
|
uint flag |
4字节 |
|
|
uint64 timestamp |
时间戳8字节 |
|
|
real2 vStart |
经纬度最小范围8*2字节 |
|
|
real2 vEnd |
经纬度最大范围 8*2字节 |
|
|
LevSnap levOff[24] |
级别索引,8 * 24 字节 |
|
|
char _reserve[240] |
保留 |
|
|
数据0 |
Int4 |
4*4字节,行号,列号,级别,大小 |
|
数据 |
|
|
|
数据1 |
Int4 |
4*4字节,行号,列号,级别,大小 |
|
数据 |
|
|
|
数据… |
Int4 |
4*4字节,行号,列号,级别,大小 |
|
数据 |
|
3 如何使用数据
3.1 解压成标注金字塔瓦片
用户可以通过FEPKUNPack.exe
解压程序,将数据加压标准的金字塔瓦片,然后即可使用,导出后如下所示。
导出后可以方便的被osgEarth,cesium,argis,fastearth等软件直接加载。
缺点: 导出后,占用磁盘大小比未解压前大50%。
导出后,维护困难,因为文件很多,拷贝能都受到影响。
数据截图

3.2 API读取瓦片
使用SDK/API访问数据,为了方便大家使用,避免数据解压,可以使用FEPKReadApi
SDK读取数据,SDK使用C语言编写,接口如下所示
extern "C" { ////// 打开文件函数,可以打开索引也可以打开数据文件 /// /// 文件名称 /// 0:失败,否则成功 FEPKFile fepkOpenFile(const char* fileName); /// /// 读取索引数据函数 /// /// 索引文件指服务器托管网针 /// 列号 /// 行号 /// 级别 /// 返回文件头信息 /// true:false bool fepkReadHeader(FEPKFile file,int x,int y,int z,FEPHHeader* header); /// /// 根据文件头信息读取文件大小(瓦片数据大小) /// /// 索引文件指针 /// 文件头信息 /// 输出文件大小 /// true:false bool fepkReadDataSize(FEPKFile file,const FEPHHeader* header,uint* pSize); /// /// 读取瓦片数据函数 /// /// 索引文件指针 /// 文件头信息 /// 输入缓冲区大小 /// 缓冲区长度 /// -1:失败,0:无数据,>0 数据的真实大小 int fepkReadData(FEPKFile file,const FEPHHeader* header,void* pBuf,uint nBufLen); /// /// 关闭文件 /// void fepkCloseFile(FEPKFile file); /// /// 从一个文件夹中读取瓦片的数据头,以及瓦片的大小 /// /// 目录组,以null结束 /// 瓦片的编号 /// 瓦片的编号 /// 瓦片的编号 /// 文件头信息 /// 瓦片大小 /// 返回打开的文件 FEPKFile fepkReadTileHeader(const char** path,int x,int y,int z,FEPHHeader* header,uint* pSize); /// /// 从一个文件夹中读取 /// /// 文件句柄 /// 文件头信息 /// 输入/输出,从fepkReadTileHeader读取 /// 输入,从fepkReadTileHeader读取 /// 返回读取的长度-1,失败,0,文件内部错误,其他读取的长度 int fepkReadTileData(FEPKFile file,const FEPHHeader* header,void* pBuf,uint nBufLen); }
使用说明:
#include "FEPKReaderApi.h" #include /// 如果是SDK,非源码方式,则需要因入库 /// #pragma comment(lib,"FEPKReader.lib") int main(int, char**) { /// 1. 开发文件 FEPKFile file = fepkOpenFile("D:FEdatafepkworld.fepk"); if (file == nullptr) { return 0; } FEPHHeader header; uint nSize = 0; /// 2. 读取给定瓦片编号的文件头信息 /// 如果返回false,说明当前文件中没有给定的瓦片数据 if (!fepkReadHeader(file, 0, 0, 0, &header)) { return 0; } /// 3. 读取数据大小 if (!fepkReadDataSize(file, &header, &nSize)) { return 0; } /// 申请空间 char* pBuf = new char[nSize]; /// 4. 读取数据 if (!fepkReadData(file, &header, pBuf, nSize)) { printf("read ok!n"); } /// 5. 释放内存 delete[]pBuf; /// 6. 关闭文件 fepkCloseFile(file); return 0; }
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
随着数字化时代的到来,企业对于数据的需求越来越大,同时也对数据的安全性和隐私性提出了更高的要求。传统的数据中心已经难以满足企业对于数据处理和存储的需求,因此边缘计算应运而生。边缘计算是指将计算和数据存储移动到网络的边缘,即设备或终端,以提高数据处理和响应速度,…
